8 月 10 日,宁波高架发生一起小鹏 P7 追尾致人死亡的事故。
发生事故的原因主要有两点,一是被撞车辆是静止的。二是被撞人员站在车后。离车很近的地方是水泥护栏,还有一个人蹲着,离被撞车很近。

即便这次事故,车主没有开启 NGP 功能,AEB 系统也应该起作用,但上述的原因让 AEB 系统失效了。
有人可能会说时速 80 公里超出了 AEB 的上限,早期的 AEB 系统的确如此,上限一般是时速 60 公里。
2020 年后的新一代 AEB 则不然,在速度上限内是刹停,也就是刹车力度会达到最大,超过上限则是减速。
以特斯拉为例,如减速 50 公里,那么系统则在时速 110 公里情况下触发 AEB,最多减速至时速 60 公里。
有些如奔驰,AEB 速度上限高达时速 110 公里。
还有些车型把这一部分单独抽出,称之为碰撞缓解,实际就是加强版的 AEB。
只减速不刹停,这样做也是为了避免高速情况下后车的追尾。

蔚来和特斯拉都发生过撞静止车辆的事故,特斯拉的次数尤其多,多次撞向白色卡车和消防车。
在封闭场地测试时,我们可以看到静止车辆或行人都能触发 AEB,即使最廉价的车型都能做到刹停。
但为何在真实道路上,遇到静止目标时,AEB 不行了?
01、分离动态目标的常见三种方法
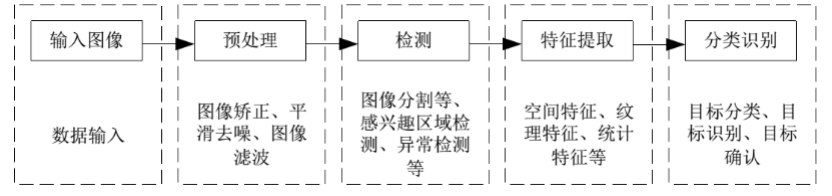
图像识别流程
我们先从先从图像识别流程和运用目标分离方法来看看自动驾驶系统是如何识别和处理障碍物的。
上图为机器视觉的处理流程,其主要过程为输入图像,对输入的图像进行预处理。
预处理之后的图像,再对其进行ROI区域检测或者异常检测,对已经检测出来的区域进行特征提取分类识别等。
系统对运动目标是需要特别重视的,会优先处理运动目标,因此第一步要将运动目标从背景图中分割出来,有些系统为了避免误动作,干脆将静态目标过滤掉。
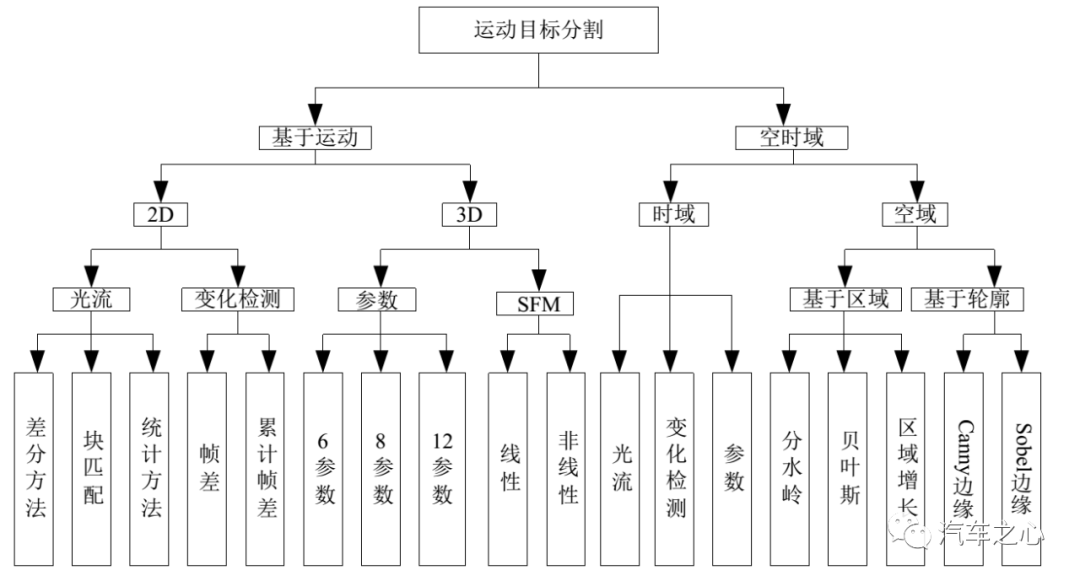
运动目标分离方法
分离动态目标最常见的三种方法是帧差法、光流法和背景差法。
考虑到实时性和成本,目前业内大多采用帧差法。这种方法对运算资源消耗最少,最容易达到实时性,但缺点准确度不高。
所谓帧差法,即检测相邻帧之间的像素变化。
帧差法的基本思想是:运动目标视频中,可以根据时间提取出系列连续的序列图像,在这些相邻的序列图像中,背景的像素变化较小,而运动目标的像素变化较大,利用目标运动导致的像素变化差,则可以分割出运动目标。
帧差法可以分为两帧差分法与三帧差分法。
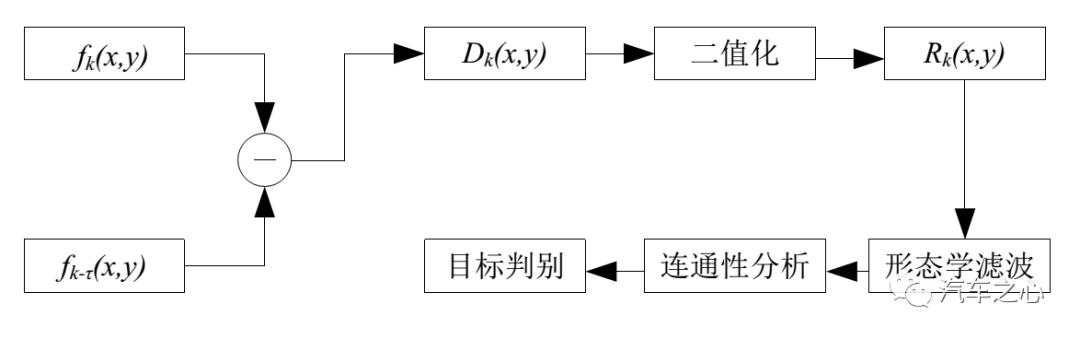
两帧差分法
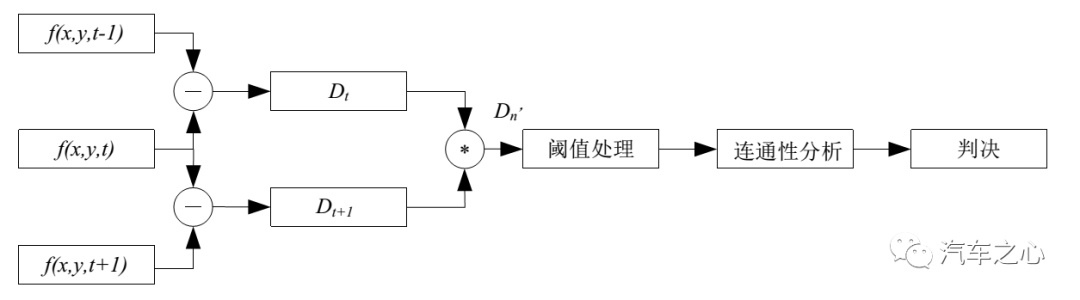
三帧差分法
两帧差分法就是将视频采集到时序列图像的相邻两帧图像进行差分。
对相邻的两帧图像进行差分,可以在任何具有复杂的图像特征(例如,纹理特征、灰度均值等) 上进行。
因此,只要明显区别与背景的运动物体均可检测出来。
根据给定的阈值,对差分结果二值化:
若差值图像大于给定阈值,则认为该像素点是前景目标中的点,并将该像素点作为运动目标的一部分;
若差值图像小于给定阈值,则认为该像素点属于背景目标点,从而将运动目标从背景目标中分割出来。
图像进行阈值分割之后,通常都带有噪声,因此需要使用形态学滤波的方法对噪声进行衰减。衰减噪声后得到的图像运动目标会存在一些空洞,需要进行连通性处理,最后才得到判别目标。
阈值设定太低,检测不到目标。设定太高,会被检测为两个分开的物体。
同时对于比较大、颜色一致的运动目标,如白色大货车,帧间差分法会在目标内部产生空洞,无法完整分割提取运动目标。
分离出动态目标,对目标进行识别并探测其距离,如果动态目标都已经处理完毕,这才开始处理静态目标。而在封闭场地测试场里,只有一个目标,很轻松就能分离出背景,只处理静态目标。
而在真实道路上,静止目标比移动目标的检测要晚大约 2 到 4 秒,这次发生事故时,小鹏 P7 的时速是 80 公里,也就是 44 到 88 米。
光流法是利用图像序列中像素在时间域上的变化以及相邻帧之间的相关性,来找到上一帧跟当前帧之间存在的对应关系,从而计算出相邻帧之间物体的运动信息。
研究光流场的目的就是为了从图片序列中近似得到不能直接得到的运动场,其本质是一个二维向量场,每个向量表示场景中该点从前一帧到后一帧的位移。对光流的求解,即输入两张连续图象(图象像素),输出二维向量场。
除了智能驾驶,体育比赛中各种球类的轨迹预测,军事行动中的目标轨迹预测都能用到。
光流场是运动场在二维图像平面上的投影。因为立体双目和激光雷达都是 3D 传感器,而单目或三目是 2D 传感器,所以单目或三目的光流非常难做。
光流再分为稀疏和稠密(Dense)两种,稀疏光流对部分特征点进行光流解算,稠密光流则针对的是所有点的偏移。
最常见的光流算法即 KLT 特征追踪,早期的光流算法都是稀疏光流,手工模型或者说传统算法。
2015 年有人提出深度学习光流法,在 CVPR2017 上发表改进版本 FlowNet2.0,成为当时最先进的方法。截止到现在,FlowNet 和FlowNet2.0 依然是深度学习光流估计算法中引用率最高的论文。
传统算法计算资源消耗少,实时性好,效果比较均衡,但鲁棒性不好。
深度学习消耗大量的运算资源,鲁棒性好,但容易出现极端,即某个场景非常差,但无法解释,与训练数据集关联程度高。
即使强大的英伟达 Orin 芯片,在 FlowNet2.0 上也无法做到实时性,毕竟 Orin 不能只做光流这一件事。
光流法比帧差法准确度要高,但会大量消耗运算资源。
02、4D 毫米波雷达会漏检吗?
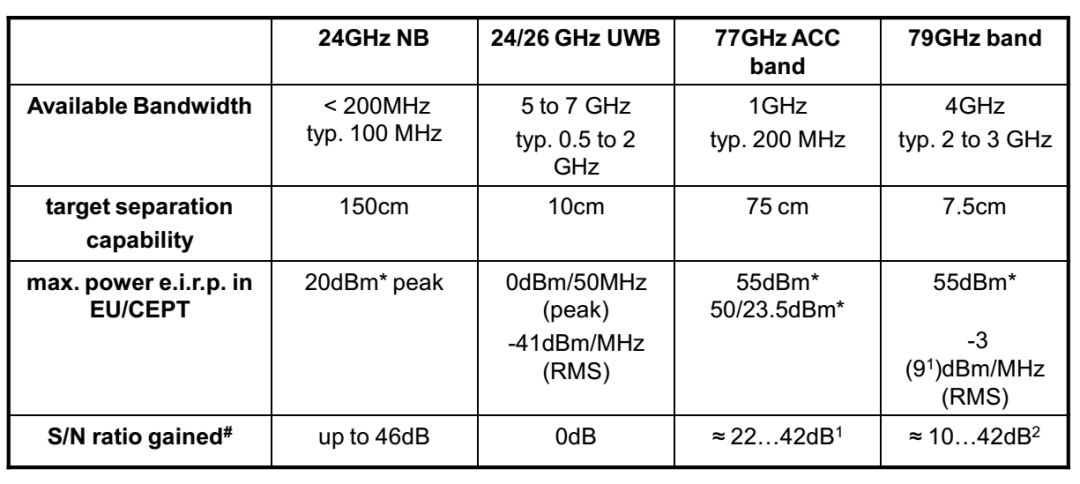
四种毫米波雷达性能对比
目前典型的 76GHz 毫米波雷达的带宽是 500GHz
大部分毫米波雷达的带宽是 500MHz,也就是 0.5GHz,目标分离度是 150 厘米。
也就是说,1.5 米内的两个目标,毫米波雷达会识别成一个——这次小鹏 P7 发生的事故也是如此,车辆很靠近水泥护栏,很有可能会被认为是一个目标。
特斯拉最近也在研发毫米波雷达,其带宽应该是 500MHz,全球最先进的 4D 毫米波雷达即大陆汽车的 ARS540,也是 500MHz。
博世还未量产的 4D 毫米波雷达是867MHz,比特斯拉和大陆都要好,缺点可能是功耗太高,射频输出功率达到惊人的 5495 毫瓦,整体功耗估计有 30-60 瓦。
ARS540 的射频输出功率是 1143 毫瓦,整体功耗大概 10 瓦。这对一个一直常开的传感器来说功耗似乎太高了。
再有就是虽然 60GHz 以上波段无需牌照,但超过 1GHz 的带宽,可能还是会有监管,在没有明确政策出台前,业界不敢研发这种高宽带雷达,万一禁止就白研发了。
因为目标分离度的问题,我估计厂家为了避免误动作,未必敢将 4D 毫米波雷达单独做为 AEB 的触发条件,肯定要以视觉为准。
除了静止目标原因外,这次小鹏 P7 在事故发生前,被撞者走到车尾。这就形成了一个很罕见的目标,既像车又像行人,在这种情况下,就会出现漏检。
03、基于单目、三目的机器视觉,有着天然缺陷
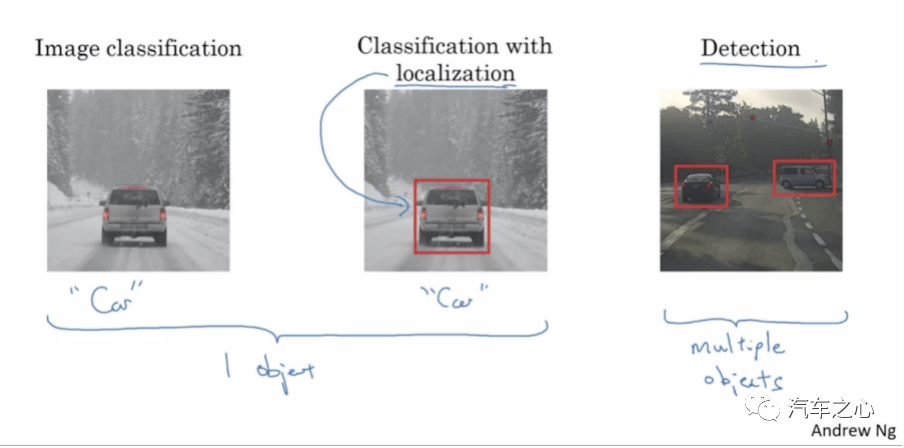
基于单目或三目的机器视觉,有着天然的无法改变的缺陷,这个缺陷表现为识别或者说分类与探测是一体的,无法分割,特别是基于深度学习的机器视觉。
也就是说,如果系统无法将目标分类(也可以通俗地说是识别),也就无法探测。
换句话说,如果系统无法识别目标,就认为目标不存在。车辆会认为前方无障碍物,会不减速直接撞上去。
什么状况下无法识别?
有两种情况:
第一种是训练数据集无法完全覆盖真实世界的全部目标,能覆盖 10% 都已经称得上优秀了,更何况真实世界每时每刻都在产生着新的不规则目标。
深度学习这种穷举法有致命缺陷。特斯拉多次事故都是如此,比如在中国两次在高速公路上追尾扫地车(第一次致人死亡),在美国多次追尾消防车。
第二种是图像缺乏纹理特征,比如在摄像头前放一张白纸,自然识别不出来是什么物体。某些底盘高的大货车侧面,就如同白纸,基于深度学习的机器视觉此时就如同盲人,不减速直接撞上去。
在以深度学习为核心的机器视觉里,边界框(Bounding Box)是关键元素。
在检测任务中,我们需要同时预测物体的类别和位置,因此需要引入一些与位置相关的概念。通常使用边界框来表示物体的位置,边界框是正好能包含物体的矩形框。
对单目、三目来说,其机器视觉如下图:

那么立体双目呢?
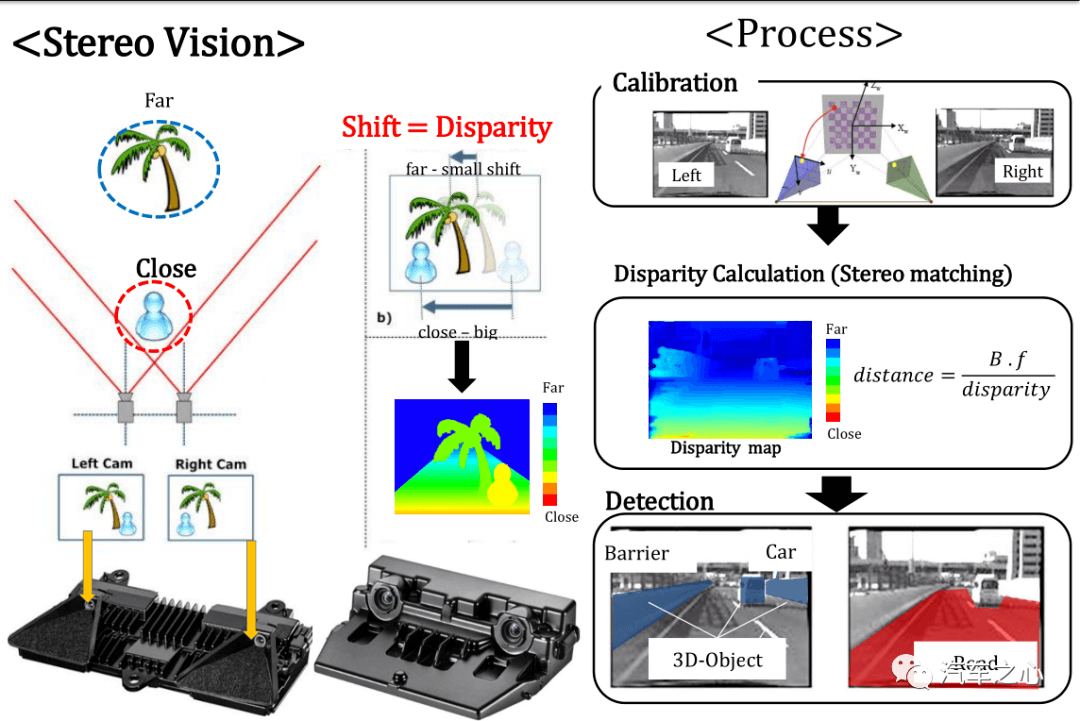
双目可以准确识别出中央隔离带,无论怎么用深度学习、单目、虚拟双目,单目和三目在这种大面积空洞无纹理特征的车侧和车顶图像前,就如同瞎子,什么也看不到。
事实上,特斯拉也有撞上中央隔离带致人死亡的事故。
立体双目的流程是这样的,如下图:
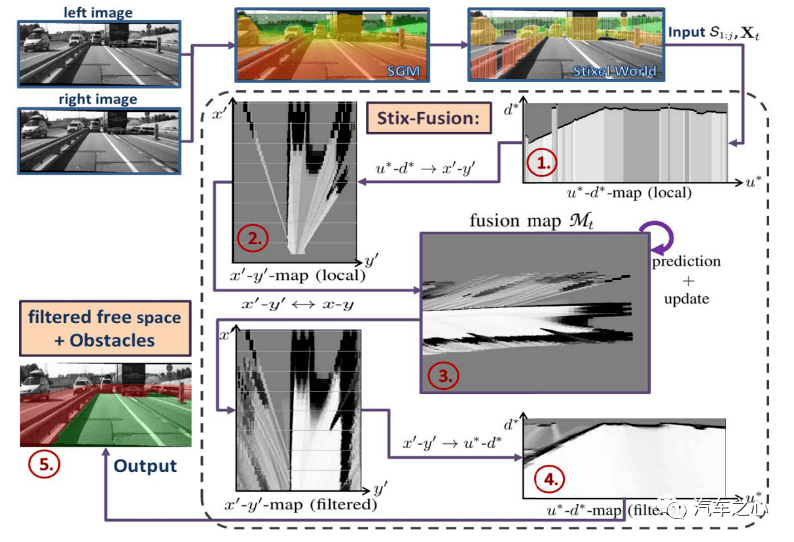
最后输出可行驶空间(free space),与单目、三目完全不同,它不需要识别,自然也不需要画出Bounding Box。
双目也有缺点,运算量太高。当然,双目不需要 AI 运算。
尽管只有奔驰和丰田用英伟达处理器处理立体双目,新造车势力除了 RIVIAN,目前都不使用立体双目(小鹏、小米可能在将来使用立体双目),但英伟达每一次硬件升级都不忘对立体双目部分特别关照。
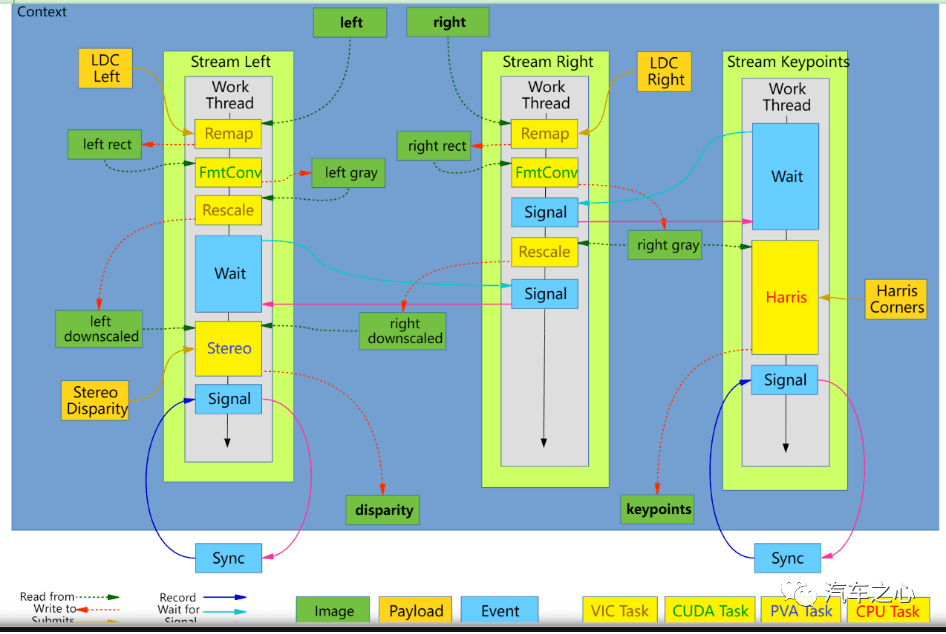
英伟达立体双目处理流程,立体双目视差的获得需要多种运算资源的参加,包括了 VIC、GPU(CUDA)、CPU 和 PVA。
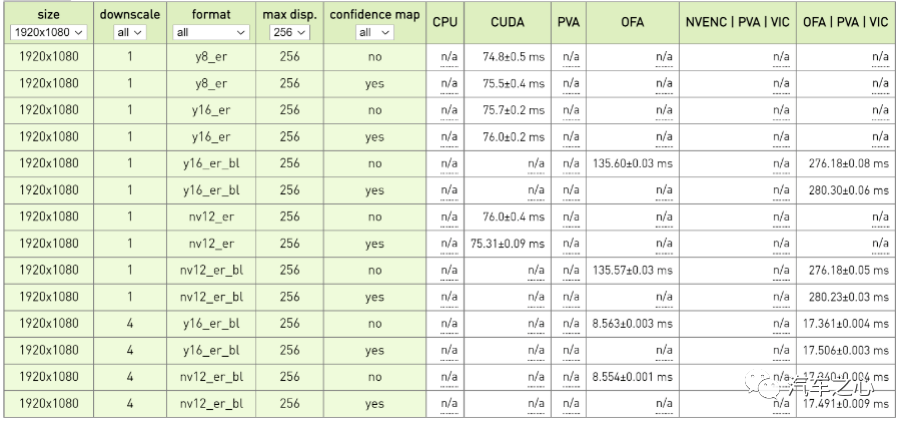
英伟达 Orin 平台立体双目视差测试成绩,要达到每秒 30 帧,那么处理时间必须低于 30 毫秒,考虑到还有后端决策与控制系统的延迟,处理时间必须低于 20 毫秒。
1 个下取样情况下,显然无法满足 30 帧的要求。
4 个下取样,不加置信度图时,单用 OFA 就可以满足。加置信图后,需要 OFA/PVA/VIC 联手,也能满足 30 帧需求。但这只是 200 万像素的情况下,300 万像素估计就无法满足了。
奔驰的立体双目是 170 万像素,输出视差图的边缘精度不会太高,有效距离也不会太远。如本文开头所说的状况,估计可以减速,但难以刹停,反应时间不够。
可以说,除了立体双目系统,遇到这次小鹏 P7 事故这样的怪异目标,都会漏检。
04、激光雷达能否避免这类事故的发生?
那么,装了激光雷达会不会避免这个事故?
恐怕也不能。
目前主流的激光雷达也是基于深度学习的,纯深度学习视觉遇到的问题,激光雷达也会遇到,无法识别就画不出Bounding Box,就认为前面什么都没,不减速撞上去。
主流的激光雷达算法经历了三个阶段:
第一阶段是 PointNet
第二阶段是Voxel
第三阶段是PointPillar
PointPillar 少了 Z 轴切割,而是使用 2D 骨干,这导致其精度下降,性能相较于纯 2D 的视觉,提升并不明显。这也就是为什么特斯拉不使用激光雷达。
而不依赖深度学习、具备可解释性的多线激光雷达算法,目前还未见面世。博世、奔驰和丰田在研究,这会是一个漫长的过程。
深度学习太好用了,不到半年,一个普通大学生就可以熟练调参。
深度学习淘汰了几乎所有的传统算法。
眼下,几乎没有人研究激光雷达的传统算法,比如激光雷达的强度成像。
目前,智能驾驶最关键的问题是过于依赖不具备解释性的深度学习,或者说深度神经网络,也就是大家常说的 AI——这可能导致无人驾驶永远无法实现。
来源:第一电动网
作者:汽车之心
本文地址:https://www.d1ev.com/kol/182415
文中图片源自互联网,如有侵权请联系admin#d1ev.com(#替换成@)删除。




先估价再买车,买的放心开的安心
您的询价信息
已经成功提交我们稍后会联系您进行报价!







 京公网安备
11010502033163号
京公网安备
11010502033163号