在此前的《数据闭环工具链,智驾领域的下一个竞争点?》中,我们曾谈到,随着大模型以及AI生态的发展,企业处理大规模数据和运用的能力开始成为关键。
尤其当ChatGPT出现后,大家发现,从GPT-2到GPT-3,模型结构上的改变微乎其微,更多的精力放在了清洗高质量、大规模训练数据上,数据集的量从40GB增加到45TB。而从GPT-3到GPT-4,不再是单纯数据量的增加,而是全网数据的利用,包括数据训练策略、数据清洗、数据整理、数据分布以及人类反馈等等。
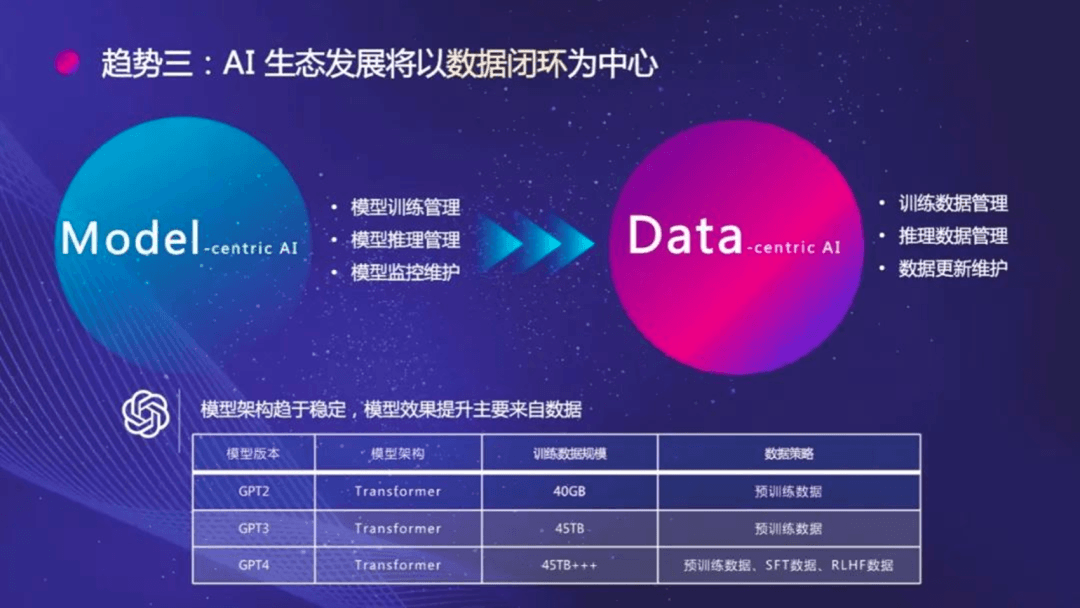
吴恩达在2021年提出的Data-centric AI(以数据为中心的人工智能)主张,正在被越来越多地实践。
过程中,随着数据量的不断增长和模型复杂度的提升,“数据债”——正在成为算法工程师们面临的隐秘又难解的挑战。
为了解决数据债问题,AI数据技术公司星尘数据带来了面向AI的数据闭环产品——MorningStar。
1
—
为解决数据债而生
数据债一词源于技术债,是一种新型的技术债务,指的是由于对数据资产的维护不足导致的数据质量问题。
一个算法的上线部署需要经历需求定义、方案制定、数据采集、数据标注、模型设计、训练、指标测试、推理优化等等。在各个环节中,各个角色跨组织协同会导致企业数据债的产生。
简单来说,数据债指的是企业当前状态与最大化数据价值之间的差距。数据债包含算法和其他部门的认知差别、项目时间上的认知差别、文档和数据语义的差距、不同数据集定义之间的差距等。数据债不仅会导致数据价值无法释放,运营成本不断增加,还会影响模型的上线和迭代效率。
据OpenAI内部工程师透露,由于数据历史语义丢失,ChatGPT之前曾一度面临模型无法复现的问题。
“MorningStar专注于发现数据价值,加速模型迭代,为AI2.0打造以数据为中心的协作环境,消除数据债。”星尘数据创始人&CEO章磊表示。“MorningStar全面覆盖AI全生命周期的数据闭环,不仅能确保数据的统一管理和快速迭代,还集成了主流难例数据的发现策略,支持AI算法的高效迭代,为企业提供一个全面的数据维护工具,以满足其对数据管理和价值挖掘的需求。”

△星尘数据创始人&CEO章磊
在章磊看来,未来算法的发展将类似于互联网时代的快速迭代,不是改变模型架构,而是优化数据。“通过AI可以打造企业的超级员工,使企业生产力提升10倍。这将使企业成为一个24小时不停运转的超级大脑,所有员工围绕这个大脑不断沉淀数据和大模型,将大模型的能力赋能给企业。” 章磊说道。
超级员工可以帮助企业完成研发、代理、销售产品、财务等任务。但关键在于什么样的数据能够打造出超级员工。
“只有‘黄金数据集’才能有效帮助模型迭代。如何准备和管理这些数据集已成为自动驾驶公司和车厂的核心竞争力。”
2
—
发现数据价值
从“数据管理”这个关键词,我们很容易想到这一领域的独角兽公司Databricks,其主要业务是帮助企业准备用于分析的数据,支持采用机器学习和数据驱动的决策,还使数据科学能够与数据工程和其他业务部门协作来构建数据产品。
从描述来看,Databricks与MorningStar的功能类似,但实际上,两者有着本质的区别。
“首先,MorningStar是一个AI数据管理系统,服务于机器和算法,而Databricks则是为人类管理和分析数据而设计的。其次,Databricks解决的是海量数据的快速查询和分析检索能力,而MorningStar的定位在于数据价值的发现和迭代,以支持模型训练。”章磊解释道。
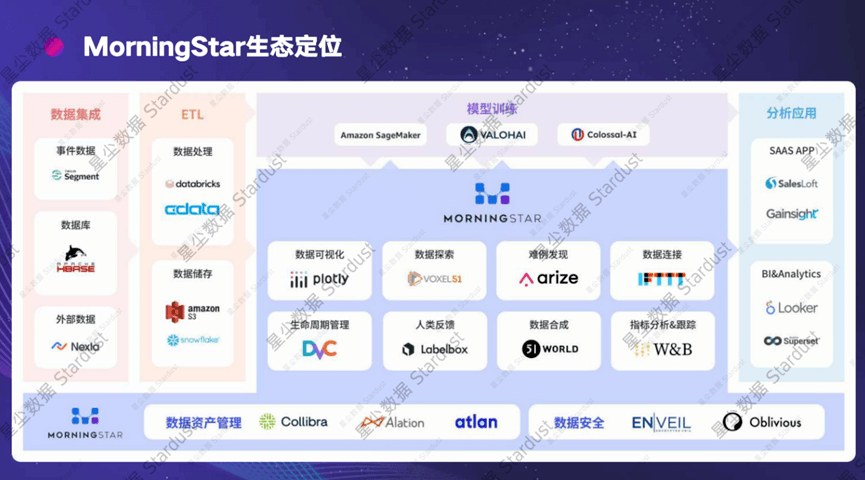
△MorningStar生态定位
据介绍,MorningStar的功能包括数据价值发现、数据迭代优化、数据可视化、数据生命周期管理、数据探索能力、数据反馈、数据合成、算法指标跟踪和数据连接等(上图蓝色部分)。
如果以模块来划分,则是以下三大功能模块:
一、以数据为中心的协作。目标是促进企业内部数据的精确认知,包括多维度、细颗粒度的语义信息,以提高跨部门的协同效率。其中可视化工具可以帮助用户更好地理解数据分布,而多模态场景标签和语义检索工具则增强了数据的可发现性。
二、人类反馈。在模型生产、开发和使用过程中,需要人类的信息和认知来提高大模型的性能。这包括对难例数据进行确认反馈、合成数据的质量反馈,以及大模型的反馈。星尘数据的自动化标注平台Rosetta已嵌入该模块。
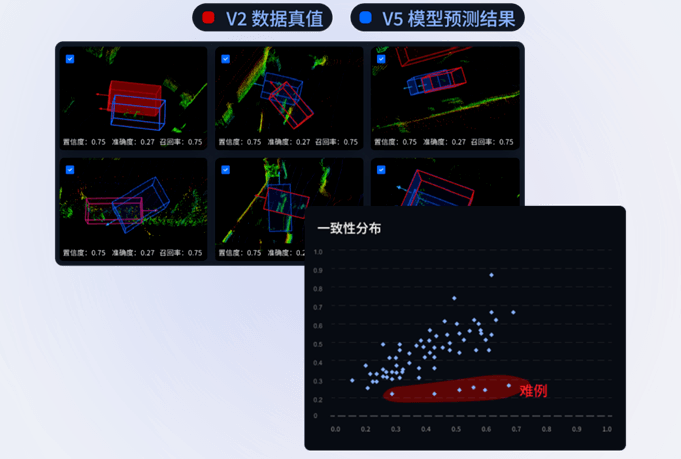
△通过数据分布发现难例
三、指标追踪和模型分析。星尘数据联合国内外知名机构和学者打造的CIF-Bench已经正式发表,同时也将上线MorningStar。这是一套对大模型能力进行完整评估的benchmark系统,重点评价了20个基础维度,考察模型在150个任务上的指令遵循能力,能系统帮助用户评估模型能力,从而知道哪些数据能够提升模型价值。
从MorningStar生态定位图中也能看到,每个单一功能都有相应的开源工具可以替代。但MorningStar的核心在于数据闭环与迭代,而不仅仅是单一功能的实现。
“我们希望与生态合作伙伴一起合作,整合整体价值,而不仅仅是单一模块。从数据集成到ETL(提取、转换、加载),再到数据训练和模型训练,模型和数据之间有着密切的互动。在此之前,很少看到有一家公司能够把所有的模块都整合起来。” 章磊说道。
3
—
多元化布局
当前这个阶段,算力和基座模型都可以直接购买,公域数据也逐渐成为标品,私域数据正在成为企业最核心的竞争力。
“但数据量并不等于数据质量,企业只有自身具备沉淀私域高质量数据的能力、即可直接用于生成超级员工的数据,才能获得市场竞争的核心优势。” 章磊说道
从这个角度上看,具有数据价值发现的数据管理平台,成为了必然的趋势和全新挑战。
MorningStar 的推出,正是因为捕捉到了这样的需求,不仅能够支持企业高效迭代AI数据的关键环节,避免数据债风险的积累,还能减少低价值数据成本的浪费,解决模型训练和应用效果反馈链条过长等问题。
据悉,针对机器学习算法工程师、业务人员、技术管理人员等不同的用户,MorningStar也推出了不同的服务形式,包括私有化部署、SaaS化在线服务和开源版本。旨在降低数据门槛,特别是对高校和科研机构的支持。目前,软件版本已经准备就绪,SaaS版本预计将在下个季度推出。
来源:第一电动网
作者:智车星球
本文地址:https://www.d1ev.com/kol/222572
文中图片源自互联网,如有侵权请联系admin#d1ev.com(#替换成@)删除。




先估价再买车,买的放心开的安心
您的询价信息
已经成功提交我们稍后会联系您进行报价!








 京公网安备
11010502033163号
京公网安备
11010502033163号