国产,存算一体,基于 12nm 工艺制程,在 Int8 数据精度下实现高达 256TOPS 的物理算力,典型功耗低至 35W,能效比高达 7.3Tops/W,高计算效率、低计算延时、低工艺依赖……
这是5月10日 ,后摩智能正式发布的首款存算一体智驾芯片鸿途™H30的关键参数,是不是让你眼前一亮?

△后摩智能创始人兼CEO吴强
这款芯片的关键词有两个——“存算一体”和“智驾”。
后者并不陌生,且已有特斯拉FSD、英伟达Orin、地平线征程5等代表产品。因此,想要在这些产品中留下印象,“存算一体”是关键。
1
—
什么是存算一体?
存算一体这个概念最早可以追溯到上个世纪,没有很快兴起主要有两个原因:
一是当时存算一体虽然可以解决部分性能提升问题,但能解决的部分在整个系统中只占10%-20%,意义不大。更重要的一点是,过去几十年摩尔定律还在持续被验证,行业并不需要架构的创新,只需要每一到两年升级一代芯片工艺,就能实现性能的快速提升和成本的同步降低。
但随着摩尔定律逐渐走到尽头,以及近几年云计算和人工智能应用的快速发展,数据洪流扑面而来,数据搬运慢、搬运能耗大等问题成为了计算的关键瓶颈。

△冯诺依曼架构示意图
在经典的冯诺依曼架构中,数据存储与数据处理在物理上是两个相互分离的单元,在数据处理过程中,处理器与存储器之间需要不断地通过数据总线交换数据。
从下图不难看出,算力发展速度远超存储器,导致存储器的数据访问速度愈发跟不上处理器的数据处理速度,后者性能与效率受到严重制约,这就是我们常说的“存储墙”。
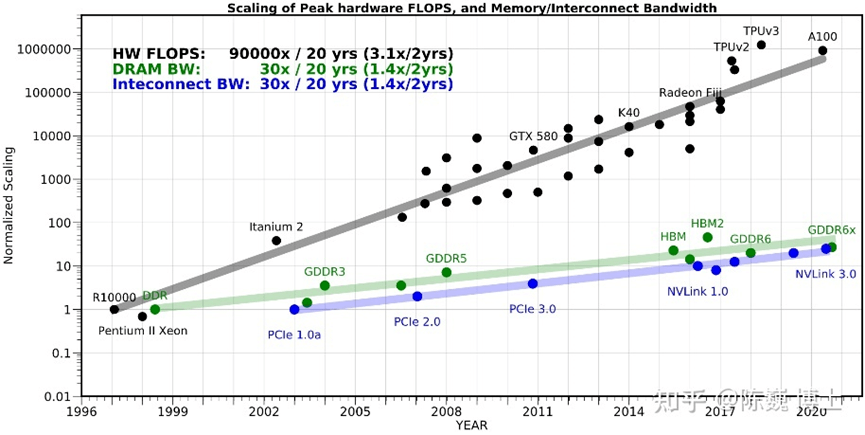
△截图来自《存算一体芯片技术及其最新发展趋势》
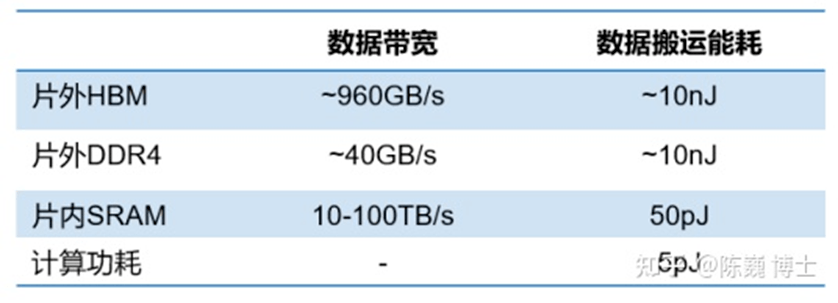
另外,从处理单元外的存储器提取数据,搬运时间往往是运算时间的成百上千倍,整个过程的无用能耗大概在60%-90%之间,能效非常低。“功耗墙”,同样成为了限制芯片发展的因素。
解决数据在计算单元和存储单元之间频繁的移动问题,成了深度学习加速的最大挑战。
过去几年,行业尝试了多种方法,例如为了减少数据搬运的大粒度的指令(集)或专用指令(集)、访存优化(替换/预取)、调度优化、内存/缓存压缩、低摆幅电路、大缓存技术等;或是提高并行度的SIMD、SIMT、STMD、指令预测等技术;还有降低数据进度、使用新型封装、器材或材料等方式,但都未能从根本上解决数据密集型算力的问题。
突破两堵墙,依然是关键,此时,存算一体架构开始重入行业视野。
2
—
以场景做选择
存算一体可以简单从字面理解为在存储单元中潜入计算能力,以新的运算架构进行二维和三维矩阵乘法/加法运算,从本质上消除不必要的数据搬移的延迟和功耗,大幅提高AI计算效率,降低成本。
从实现路径上,虽然没有统一的定义,但根据计算单元与存储单元的关系主要有查存计算、近存计算、存内计算和存内逻辑,而目前行业中使用最多的是近存计算和存内计算。
前者计算操作由位于存储区域外部的独立计算芯片/模块完成,通过先进的封装方式以及合理的硬件布局和结构优化,增强二者间通信带宽,增大数据传输速率,进而提高数据处理效率。这种架构设计的代际设计成本较低,适合传统架构芯片转入。典型代表是AMD的Zen系列CPU,2021年年末,阿里达摩院推出基于SeDRAM的3D堆叠芯片也是采用了该技术路径。
而存内计算由位于存储芯片/区域内部的独立计算单元完成,存储和计算可以是模拟也可以是数字。
国外的Mythic,千芯、闪亿、知存以及这次发布新产品的后摩智能都是这条路径上的代表企业。
除了技术路径,在存储器选择上,存算一体芯片也有两个主要方向:
一、易失性存储器,但在计算上具有突出的优势的,主要有SRAM静态随机存储器和DRAM动态随机存储器;
二、非易失存储器,在芯片的成本上具有一定优势的,主要有RRAM 阻变随机存储器、MRAM 磁性随机存储器、FeRAM 铁电随机存储器、PCM 相变存储器、FLASH 闪存等。
世上没有完美的选择,自然没有一种存储器具备在所有场景下的绝对优势。因此,芯片企业存储器件的选择,以及数字存算还是模拟存算的选择,都与应用场景密切相关。
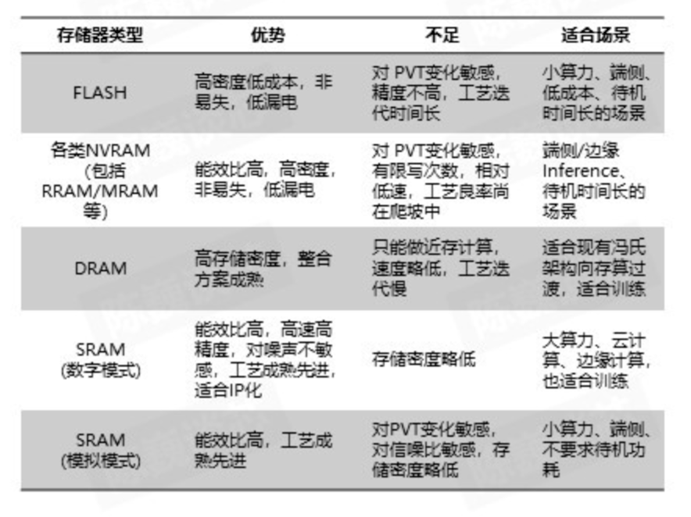
△截图来自《存算一体芯片技术及其最新发展趋势》
对于把重点放在智驾的后摩,SRAM显然是其最优解。
3
—
以新型架构扩展算力
根据后摩智能联合创始人兼研发副总裁陈亮介绍,后摩面向智能驾驶场景打造了专用 IPU(处理器架构)——天枢架构,采用多核、多硬件线程的方式扩展算力。
一个芯片里有4个完全相同的IPU核,每个IPU核内部,又由4个完全相同的Tile组成,每个Tile对应一个或者多个硬件线程,每个Tile的内部又包括了CPU、Tensor Engine、Special Function Unit, DMA和Vector Processor等,其中Tensor Engine就是由存算电路和一个Feature Buffer,还有相应的一些控制电路组成,这些计算单元在CPU的统一调度下进行计算。
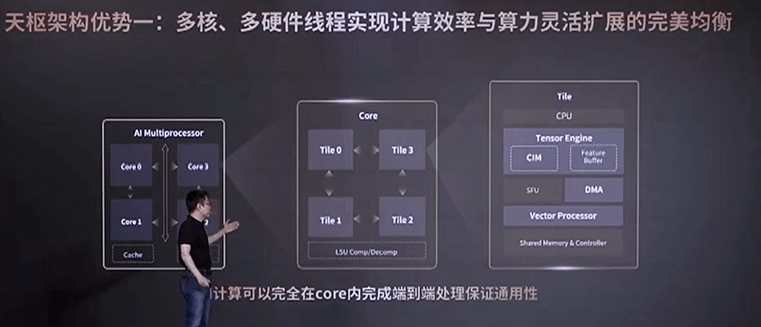
“在SRAM电路旁边,我们加入了一些定制化的电路结构,包括乘法器、加法数、累加器等,这些定制化的电路结构和SRAM的电路整合在一起,就实现高效的存内并行计算。存储器单元中存储的数据,可以在同一时刻一起读出来参与计算。” 陈亮解释说,“定制化的乘加电路和传统的SRAM Bit Cell电路完全融合在一起,带来更加规整的电路结构,因而就有更紧凑的电路设计,面积也就相应减少了。不管是传统的SRAM电路,还是定制化的计算电路,都是纯数字的设计,因而不会有任何的计算误差。”
现场,陈亮还展示了后摩智能存算一体电路的一些技术参数与业界5nm工艺的对比。后摩这款芯片在采用相对更成熟的12纳米制程后,按陈亮的说法,实现了“既要马儿跑,又让马儿少吃草”的结果。
“我们已经在28纳米、22纳米、16纳米、12纳米等不同工艺下进行过流片和测试。”

△后摩智能联合创始人兼研发副总裁陈亮
据悉,目前鸿途™H30 已成功运行常用的经典CV网络和多种自动驾驶先进网络,包括当前业内最受关注的 BEV 网络模型以及广泛应用于高阶辅助驾驶领域的 Pointpillar 网络模型。以鸿途™H30 打造的智能驾驶解决方案已经在新石器的无人小车上完成部署,这也是业界第一次基于存算一体架构的芯片成功运行端到端的智能驾驶技术栈。
4
—
量产,漫长的季节
本次发布会,后摩智能同步推出了基于鸿途™H30 芯片打造的智能驾驶硬件平台——力驭®,CPU 算力高达200 Kdmips,AI算力达256Tops(INT8物理算力),支持多传感器输入。官方介绍,力驭®平台功耗仅为 85W,可采用更加灵活的散热方式,实现更低成本的便捷部署,有利于推动大算力智能驾驶场景的普及应用。
此外,为了让客户拥有更好的产品使用体验,后摩智能还基于鸿途™H30 芯片自主研发了一款软件开发工具链——后摩大道™,支持 PyTorch、TensorFlow 、ONNX 等主流开源框架,编程兼容 CUDA 前端语法,同时支持 SIMD 和 SIMT 两种编程模型,兼顾运行效率和开发效率,以无侵入式的底层架构创新保障了通用性的同时,进一步实现了鸿途™H30 的高效、易用。
据后摩智能联合创始人兼产品副总裁信晓旭透露,鸿途™H30 将于6月份开始给 Alpha 客户送测。同时,后摩智能的第二代产品鸿途™H50 已经在全力研发中,将于2024年推出,支持客户 2025年的量产车型。

△后摩智能联合创始人兼产品副总裁信晓旭
行业对大算力芯片需求的激增,给了后来者后摩智能迎头赶上的空间,不到半年时间完成芯片流片、点亮到发布,后摩对于时代给予的机会展现出了十分积极的姿态。不过这还仅仅是开始,想要进汽车供应链,产品送测后还有定点、订单、小规模试装,然后才是规模量产,量产后还要看终端的销量……过程中的变数依然很大。
另一个重大课题,就是让每一家科技公司都头痛的工程交付。就像发布会现场一位下游需求方说的,“存算一体是个新的方向和尝试,但关键要看量产落地的能力。”
对于后摩,依然有一个“漫长的季节”,度过之后,将是另一片天地。
来源:第一电动网
作者:智车星球
本文地址:https://www.d1ev.com/kol/202412
文中图片源自互联网,如有侵权请联系admin#d1ev.com(#替换成@)删除。




先估价再买车,买的放心开的安心
您的询价信息
已经成功提交我们稍后会联系您进行报价!








 京公网安备
11010502033163号
京公网安备
11010502033163号