作者 | 张祥威
编辑 | 德新

“最高物理算力256 TOPS,典型功耗35W,基于12nm制程工艺。”
5月10日,后摩智能发布首款基于存算一体架构的智驾芯片——鸿途™H30,并公布上述关键指标。
算力、数据和算法,并称AI的三大核心要素。其中,算力属于基础设施,又被称为新时代的原油。随着ChatGPT语言大模型的出现,AI迎来了自己的iPhone时刻,算力的重要性也愈加凸显。
走在最前的英伟达,不断推出更高算力的芯片,一些玩家选择了跟随,另外一些选择另辟道路,通过存算一体、量子计算等突破算力瓶颈。
后摩智能的存算一体芯片H30,便是一道新的解题思路,也让主机厂、Tier 1有了更多新选择。
英伟达旗舰AI芯片H100,随着AI生成式大模型受到广泛关注,售价近期一度被炒到46000美金。
H100是英伟达于去年推出的一款全新架构的GPU芯片。
8块H100,再加上4个NVLink可以组合一个DGX H100,AI算力高达32 PetaFlops。英伟达CEO黄仁勋称,20块H100就可以承载全球互联网的流量。
热衷自动驾驶的特斯拉CEO马斯克,不久前购买了数千块H100,笑称“看起来每个人和他们的狗此时都在买GPU。”
H100大热,体现了市场对于 芯片算力需求飙升,时代进入了一个AI爆发的新阶段。
不过,算力飙升后也让大家看到了芯片面临的瓶颈,即: 存储墙和功耗墙。
目前市面上的大多数芯片,均基于1945年提出的冯·诺依曼计算系统进行设计,计算和存储功能分别由中央处理器和存储器完成。
在这一架构中,每次计算需要先读取内存的数据,计算后再存回内存,大部分过程都在读取和存储数据。
处理器的性能跟随摩尔定律逐年提升,存储器发展滞后。
随着数据处理量增大,存储速度跟不上数据处理速度,形成了“存储墙”。数据在处理器和存储器之间来回搬运,还造成了功耗损失,形成了“功耗墙”。
为了拆掉两块墙,芯片领域提出存算一体的新架构,直接利用存储器进行数据处理,这种新架构具备 大算力、低功耗、低延时等优点。
后摩智能创始人兼CEO吴强的偶像是Jim Keller,后者是操刀过特斯拉FSD芯片的大神。Jim Keller曾说过,“不满于常规的改良,而是要做底层的重构和创新。”
因此,两年前创立后摩智能时,吴强选择了一个不依赖先进工艺,通过底层架构创新来实现AI计算效率的新方向。
这就有了后来的基于存算一体架构的鸿途™系列芯片。

“ 256TOPS是物理算力,不是市面上常说的稀疏虚拟算力。”吴强向大家介绍H30芯片时重点强调。
物理算力是指芯片的理论峰值算力。
有人将算法比作公式,将物理算力比作人的智商。从物理算力的维度,市面上已量产的国产智驾芯片,基本上都不如H30。
H30的能效比也非常高。
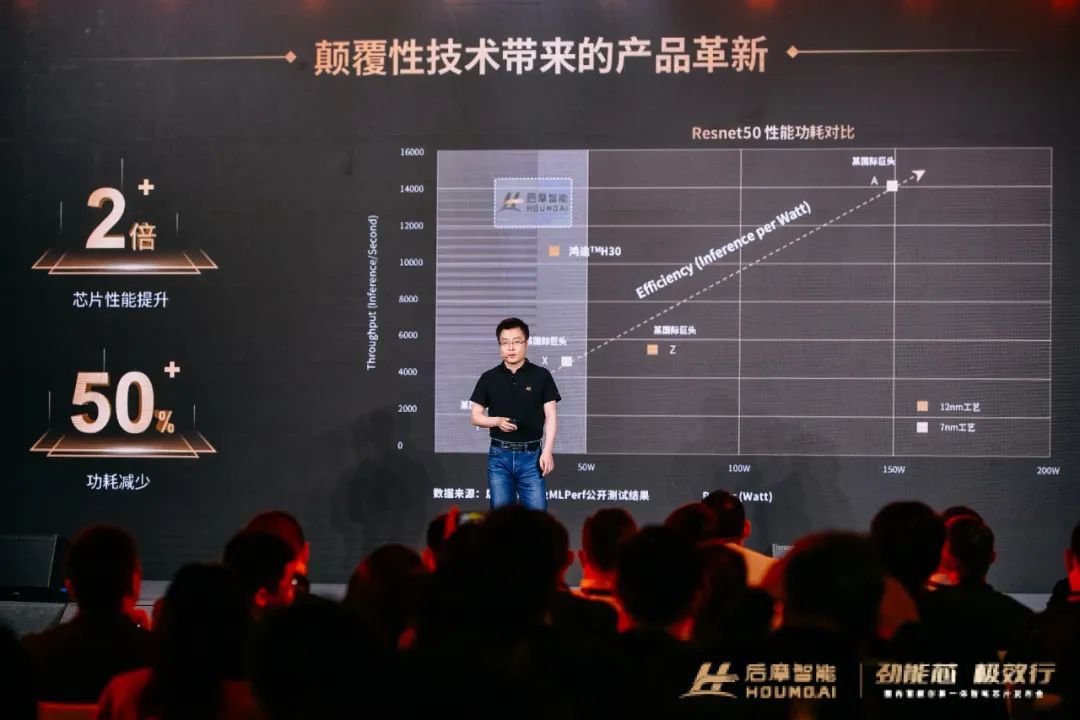
基于更为成熟的 SRAM 存储介质,采用数字存算一体架构,H30在INT8 数据精度下AI 核心IPU 能效比高达 15 Tops/W,是传统架构芯片的7 倍以上。
根据后摩实验室及MLPerf公开测试结果,以经典的基础网络Resnet50为例,在 Batch Size 等于1 和 8 的条件下,分别达到了 8700 帧/秒和 10300 帧/秒的性能,是英伟达基于8nm芯片性能的5.7倍和2.3倍。
简单来说, H30 在芯片性能提升2倍的同时,功耗减少了50%。
那么,这块芯片能做什么?
后摩智能将第一款芯片产品的应用场景选在了智能驾驶领域。
吴强认为,智能驾驶芯片一定是要 无限接近于人脑的计算方式和效率,而存算一体的价值正在于此,与智能驾驶的终局需求天然吻合。
作为一款面向智能驾驶的芯片,H30对于当下热门的神经网络均可以支持。而且,H30的架构专门针对智能驾驶场景,在低延时下性能可以更加充分地展现。
后摩智能表示,一些高阶自动驾驶领域常用的经典CV网络和自动驾驶网络等,目前已经成功移植到H30上,比如点云网络、BEV网络等。

此外,基于H30的智驾方案已经部署在后摩智能合作伙伴的无人小车上。比如,后摩智能与新石器无人车合作的无人驾驶解决方案,便是基于存算一体芯片。
基于H30,后摩智能还打造了力驭智能驾驶硬件平台,作为主机厂面向智能驾驶的参考设计和评估平台。

官方数据显示,力驭的CPU算力为200Kdmips,AI算力达到256 TOPS(INT8物理算力)。
按照规划,基于第一代产品H30的力驭计算平台将在 今年6月向Alpha客户送测。第二代产品H50将于明年一季度回片,支持主机厂客户2025年的量产车型。

让H30拥有如此成绩的,是一套全新的架构。
主流芯片产品中,英伟达、高通、地平线等自动驾驶的芯片,基于冯·诺依曼架构,也就是存储分离。
H30则基于存算一体,从架构上进行底层创新。
后摩智能联合创始人兼研发副总裁陈亮总结,H30这款芯片实现了六项技术突破:
大算力、全精度、低功耗、车规级、可量产、通用性。
后摩智能自研了IPU处理器架构,第一代IPU天枢架构专为智能驾驶打造。
天枢架构的设计思路是,采用多核、多硬件线程的方式来灵活扩展算力,AI 计算可以在核内完成端到端处理,保证通用性。
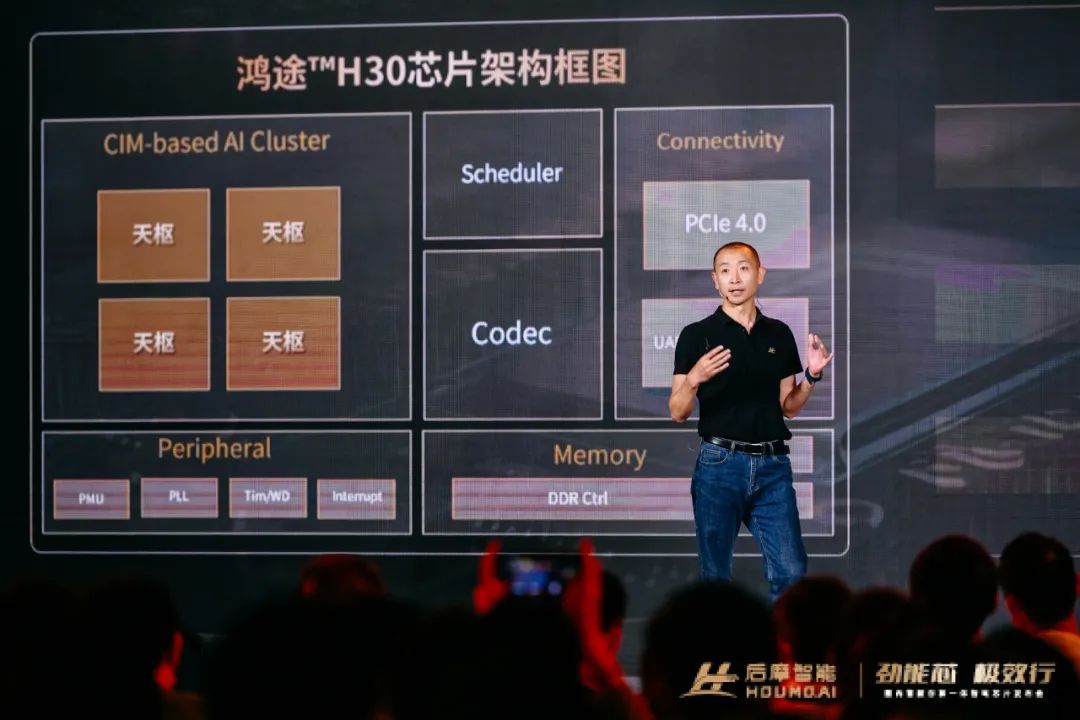
H30芯片里面有 4个IPU核,部署在系统总线NoC上。
每个IPU 核又由 4个Tile组成,每个Tile对应一个硬件线程,既可以独立进行不同任务的计算,又可以联合进行同一个任务的计算。
每个Tile的内部,包含CPU、Tensor Engine、CIM、Feature Buffer、Special Function Unit、Vector Processor、DMA、Shared Memory&Controller。
其中,CPU可以调度这些执行单元,也可以做一些对算力要求不高的计算。
这些计算单元,还可以直接共享一个多Bank的共性存储资源。
基于后摩的IPU架构,AI计算不需要在CPU、GPU、DSP等不同的处理器之间分配任务,而是可以在核内完成端到端的计算。
此外,后摩智能设计了专用的数据传输总线,搭配多通道,可以在4个Tile和各个IPU 核之间建立高速的数据传输通道。
为了发挥数据复用的特性,后摩智能还设计了多播的传输机制,一个Tile里数据,可以通过一次DMA传输,广播给其他多个Tile,从而不需要多个Tile多次读取数据。
存算一体的架构,让H30可以更好地计算与存储, AI Core计算利用率达到80%以上。
最后,由于具备良好的扩展性,让这款芯片有了更多想象空间。
据了解,后摩智能的下一代芯片,将支持扩展更多核,基于Mesh互联结构,可以将计算单元灵活配置,实现算力规模的可大可小。
可以合理推测,后摩智能的下一代架构的芯片有望支持类似GPT的大模型,甚至有可能应用于更大算力的自动驾驶场景。
实际上,存算一体领域,不止有后摩智能一家,其它还包括知存科技、亿铸科技等,不同的是,后摩智能选择了智能驾驶赛道作为落地。
随着算力需求的爆发和更多芯片产品落地,存算一体正在获得越来越多的认可。
总之,在降本增效的趋势下,拥有成本优势的存算一体智驾芯片,也让主机厂在英伟达、地平线等芯片外,有了更多新的选择。
退一步说,站在芯片安全的角度,存算一体智驾芯片可以与先进制程工艺解绑,也让智能汽车被“卡脖子”的隐患得到了一定缓解。
来源:第一电动网
作者:HiEV
本文地址:https://www.d1ev.com/kol/202289
文中图片源自互联网,如有侵权请联系admin#d1ev.com(#替换成@)删除。




先估价再买车,买的放心开的安心
您的询价信息
已经成功提交我们稍后会联系您进行报价!







 京公网安备
11010502033163号
京公网安备
11010502033163号