车端目前产生大量的数据之中,各种数据来自于不同的传感器、不同的域,自动驾驶域控制器基本已经实现了算力超过百T的资源配置,这就催生了车端数据库的需求。
智协慧同是一家聚焦汽车数据链路打造和价值挖掘的公司,拥有以车端数据库为核心的车云全栈产品,通过车云同构框架,实现结构化和非结构化数据的融合采集。智协慧同产品可轻量化部署到车端各大域控制器,实现跨域的数据采存,高效推进产品的优化迭代。
大算力催生跨域数据库需求
随着各种驾驶操控行为的信号数据需求逐渐增加,多种传感器上产生海量感知数据,车端数据价值点挖掘的需求也日渐强烈。在此背景下,智协慧同认为,存算分离的车端数据库是边缘计算的基石。
车端目前产生的大量数据来自于不同的传感器、不同的域,自动驾驶域控制器基本已经配置了算力超过百T的资源。高算力的资源以及强大的CPU是实现更多车端计算分析能力的前提,同时也催生了车端数据库的需求。
车端数据库具有降低数据存储和传输流量成本、确保数据高质量、高容错性等诸多的优点。然而,目前市场上并没有成熟的车端数据库方案,虽然有类似的产品,但都并未真正实现在量产车上的落地。

图片来源:智协慧同
目前,自动驾驶已经进入大批量量产的阶段,各大主机厂都推出了自己的数据闭环解决方案。从过去单目的纯视觉方案发展至今天多摄像头、多传感器融合的自动驾驶解决方案,部署在自动驾驶域控制器上的数据闭环解决方案能够帮助主机厂采集到车端各个与自动驾驶相关的数据。
其中的数据覆盖摄像头、毫米波雷达、激光雷达、总线等方面,涵盖了从整车测试到量产的各个阶段。同时,与智能驾驶相关的数据不仅来源于自动驾驶域,还有更多的数据来自底盘动力域、智能座舱域及网关域。
相比燃油车,电动汽车带来的是更高维度、更全方位的驾控体验,正因如此,自动驾驶数据涉及到多场景、多维度,市场需要的数据库产品必须覆盖到各个场景和维度,才能够实现数据的跨域灵活采集。
车端数据采集面临难题
自动驾驶的数据采集,目前仍面临着不少难题。
首先,在量产前测试车辆数据的获取过程中,传统的数据记录仪数据采集效率低下,同时仪器的成本非常高,采集到的数据大多是整车的全量数据。无论是流量还是云端的存储费用,以及对数据的清洗、处理、关键数据的提取、建模分析,整个流程效率以及成本都为研发团队带来困扰。
在量产车上,大规模结构化数据的获取则涉及到如何将车端高精度高质量的数据进行灵活采集,以及降低上传和存储处理的成本,这也是当前各大主机厂数据相关部门都在面临的一大痛点。
自动驾驶的第二大数据采集难点是非结构化数据获取。自动驾驶NOA、NOP方案的落地,需要不断对Corner cases(边界化难题)进行优化。对于自动驾驶而言,倘若系统没有感知出遇到了Corner cases,会带来严重的安全隐患。然而解耦一个Corner case涉及到数采复杂度、多流程、成本等多个方面的问题,往往需要以月为单位进行开发,数据层面则需要近万张训练样本和标注数据集。这些Corner case数据的采集和获取,有非常高的时间成本以及采集难度。
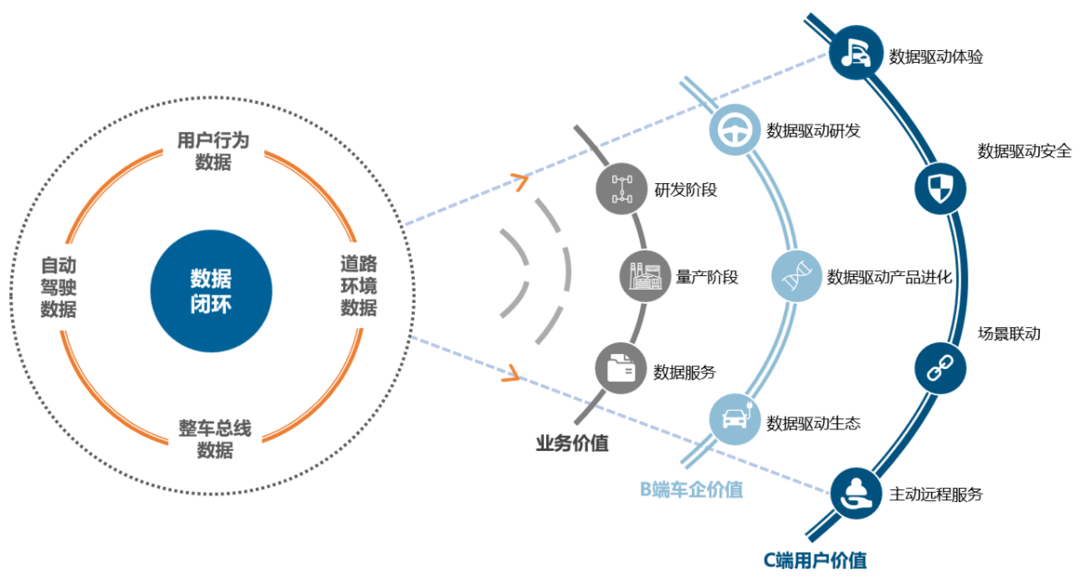
图片来源:智协慧同官网
智协慧同看到了车端数据采集的关键痛点,打造了低代码开发工具-算法直接下发-车端秒级运行-灵活数据采集/上传/存储的闭环方案,帮助主机厂进行大维度、高精度、低成本、高质量的数据采集。
针对时间成本和采集难度的痛点,智协慧同提出了一种基于车端的灵活触发机制,可以按照Corner case的具体场景来灵活定义,对数据进行从采集到应用的全流程管理,由此加速神经网络的迭代。
智协慧同的自动驾驶数据闭环解决方案会对所有的总线结构化数据、图像等非结构化数据进行共同采集,能够帮助主机厂快速提取场景化的关键数据、进行场景复现,找到神经网络算法中需要的关键迭代点以及有价值的数据。
车云链路赋能数据采存
智协慧同自动驾驶数据闭环的解决方案可以看作是一条轻量化的车云链路,得益于这一方案的众多优势,主机厂能够实现更好的关键数据抓取、数据预处理、数据标注、AI模型创建、模型训练、仿真测试等。
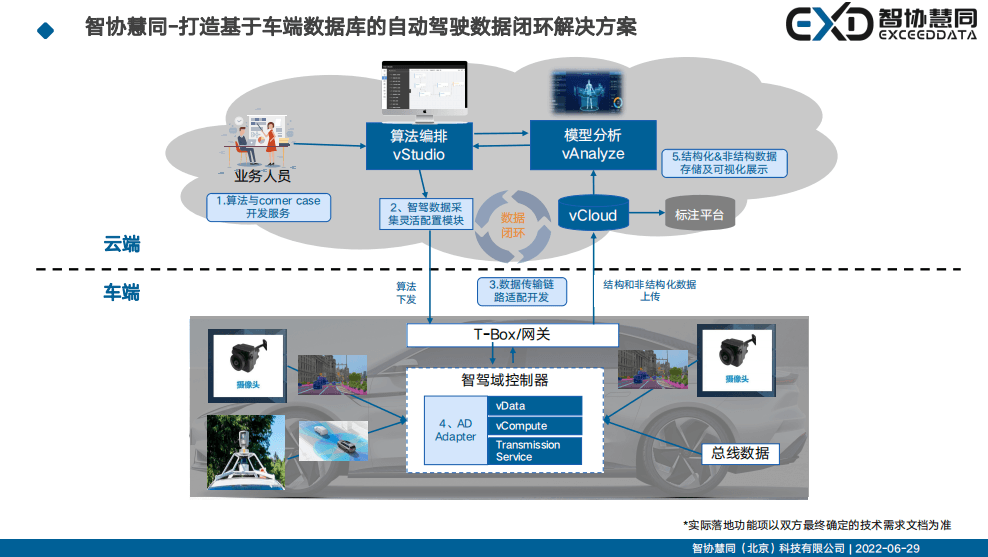
图片来源:智协慧同
首先,该数据闭环方案最大的优势,就是前文提到的,在不额外增加硬件的情况下能够实现量产车的结构化和非结构化数据采存融合。面对数十万辆级别量产智能车产生的海量多类型数据,智协慧同的方案能够对接摄像头、激光雷达、毫米波雷达、各种类型的传感器,处理图像、视频、雷达点云数据、车辆总线数据等不同类型的数据。这些数据在车端就能根据时间、场景等多维度进行系统化的管理,按照自定义的智能数据算法灵活筛选上传。使量产车的智驾数据采集,链路传输,数据计算等成本大幅降低,同时还能保证数据质量和精度。
其次,该方案能灵活定义算法与Corner cases。主机厂可以通过多次持续、快速的更新迭代来灵活响应Corner case的数据需求,其计算引擎可以实现超过数万个信号毫秒级的实时数据采集,云端开发工具生成的算法可以根据不同的车辆、场景、地域来快速下发。
第三,智协慧同的整体解决方案非常轻量化,该产品只占用自动驾驶域控制器CPU大约500兆左右的算力,以及几百兆左右的内存,能够适配不同算力的CPU。
第四点优势是触发式的图像采集。封装在车端的算子库能进行多种触发机制的前置,在触发机制条件满足的情况下,整车中来自各个部件、各个域以及各个不同的维度、不同数据类型的信号,都能通过该方案进行灵活的采集。
影子模式的触发机制是又一大优势。除了通过算法触发,数据采集还可以通过影子模式(Shadow mode)触发。换言之,在有人驾驶的情况下,车端仍会持续进行实时计算、模拟决策,并能让计算结果实时上传到云端。基于AB模式下的结果计算分析,支持主机厂车端影子模式进行场景数据的灵活采集触发。
图片来源:智协慧同官网
还有一个优势是数据分段上传。自动驾驶中图像数据、视频数据的数据量十分庞大,而车辆在不同的场景、路段中网络情况往往是不稳定的,难以实现数据实时上传。此时就可以通过预先设定的分段上传机制,对于相应的数据进行车端缓存、补传。这一机制极大地确保了关键数据从采集到上传至云端的过程中的安全问题。
软硬协同助力域控发展
电动汽车的渗透率上升,随之而来的是应用场景的增多、需求的多元化。在自动驾驶技术快速发展的同时,其中的安全性问题始终是技术发展的掣肘,Corner cases的存在更是一大安全隐患。
针对目前的Corner case,智协慧同已经实现了雨雪、Cut in/out、急加速、急转弯、隧道口等多种极限场景下的触发机制。在与客户进行共同开发和量产的实践过程中,智协慧同也锁定了后续更多的触发机制,其中覆盖了高速上急刹车、罕见的急转弯路、刹车灯亮但车辆有正向加速度等更多特殊场景。
根据智协慧同的规划,将会有上百个左右的灵活触发机制,在整车的各个场景、时段、路段,采集主机厂所需要的Corner cases数据。智协慧同将在高效率模型搭建、快速车端部署、低成本验证、灵活实现等方面持续发力,高效推进Corner cases优化迭代。
据悉,目前智协慧同是第一家能够真正实现通过车端数据库和边缘计算,完成自动驾驶数据闭环解决方案的企业。在自动驾驶数据闭环方案的量产实践中,智协慧同也积累了大量的经验,以帮助用户调整、提升在数据闭环过程中的效率。
简而言之,其经验可以总结为:轻量化数采方案降低自动驾驶域控制器负载;通过场景化的灵活数据采集和智能化的触发机制,加速自动驾驶感知算法的迭代过程;最终可根据批量下发算法功能,灵活排查问题车辆。

图片来源:智协慧同官网
作为未来汽车运算决策的中心,域控制器功能的实现不仅依赖于芯片,也需要软件操作系统、中间件、算法等多层次软硬件的协同升级。智协慧同认为,数据库作为一个效率工具,可以应用于自动驾驶以及车端的各个域控制器上,为主机厂提高数据采集、问题解耦和处理效率,为用户带来更多的体验及更好的安全。
在克服了诸多技术挑战后,智协慧同的解决方案目前已经能够从容面对行业内各大主机厂的更多需求、更多场景。当然,技术的变更总得经过市场检验。EXD自动驾驶数据闭环方案的实际表现如何,还需在搭载这一技术的车型上市后才能印证。
(以上内容来自智协慧同合伙人兼副总裁牛国浩于2022年6月29日由盖世汽车主办的2022第二届智能汽车域控制器创新-云论坛发表的《车端数据库在自动驾驶域控制器上的量产实践》主题演讲。)
来源:盖世汽车
作者:林品慧
本文地址:https://www.d1ev.com/news/qiye/180603
以上内容转载自盖世汽车,目的在于传播更多信息,如有侵仅请联系admin#d1ev.com(#替换成@)删除,转载内容并不代表第一电动网(www.d1ev.com)立场。
文中图片源自互联网,如有侵权请联系admin#d1ev.com(#替换成@)删除。




先估价再买车,买的放心开的安心
您的询价信息
已经成功提交我们稍后会联系您进行报价!

 京公网安备
11010502033163号
京公网安备
11010502033163号