今天下午,智己汽车联合 Momenta 开了一场发布会。
发布会上刘涛和曹旭东两位 CEO,分别介绍了智己汽车 IM AD 3.0 智驾系统的最新进展。比如「一段式端到端」、「本能反应主导的直觉决策能力」,「L4 自动驾驶年内取得牌照」,等等。
具体的话术不过多重复,核心概念两点:「智驾直觉时代」、「L3/L4 加速中」。
今天下午的智己,也成为了 10 月份智驾放大招的第三家车企。
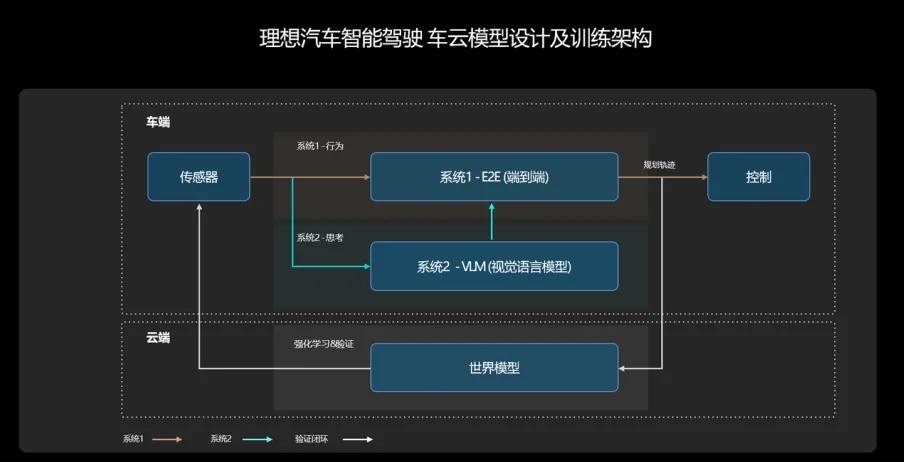
10 月 23 日,理想汽车宣布其「端到端+VLM」双系统智驾架构,伴随着 V6.4 的系统 OTA 正式向 AD Max 用户全量推送。
这也意味着理想汽车 7 月份出圈传播的「思考快与慢」技术路线,正式接收量产检验。
10 月 24 日,小鹏汽车正式宣布,即将上市的 P7+ 会首发搭载「不分场景,全量使用端到端大模型」的 AI 天玑 5.4.0 操作系统。
小鹏汽车智驾负责人李力耘表示,5.4.0 将使 P7+ 智驾的变道成功率提升 53%,绕行成功率提升 155%。
三场智驾发布,给我们的感觉是统一的:2024 年,想做好智驾传播还是太难了。
回顾今年重磅的新车发布会,舆论场上俨然成为「技术象征」、「创新代表」的智能驾驶,依然在整车发布会上放在设计、空间、性能、续航之后,让观众在最终价格之前再等 20 分钟。
但与此同时,智驾又被卷入了新造车传播逻辑的擂台中央。小视频、新定语层出不穷;今天是「One Model」、明天是「全国 XX 开」。
稳扎稳打的研发与百尺竿头的声量之间,应该如何平衡?撇去宣传浮沫,新造车目前走到了智能驾驶的哪个关口?
今天的主题是「技术殊途同归,传播先到先得」。
按照马斯克的时间表,L3 还没迎来曙光,而全世界已经熬了十年夜。
不过,进入 2024,无论是车企,还是自动驾驶软硬件供应商,都开始表露出进入新时代的兴奋和躁动。体现在传播口径上,是 L3 已经被头部新造车「定档」。
比如小鹏将百公里接管少于 1 次的「类 L3」定在了 2025 下半年;智己号称即将成为「同时具备 L2/L3/L4 能力」的车企,「L3 进入量产倒计时」。
李想本人的原话,则是「最晚明年上半年,真正有监督的 L3 自动驾驶就可以批量向用户交付了」。
新造车似乎要不约而同地冲线,而即使传播话术各异,他们的冲线方式,似乎都有相似之处。
接下来按照时间顺序聊,先下结论:对数据的处理效率,某种意义上决定着同样硬件平台下,各家高级智驾的落地速度。
然后我们回到 7 月 5 号的理想汽车智能驾驶发布会。
1. 理想「翻身仗」
这场发布会,后来被一些观点形容为「理想的翻身之战」,我们先抛开纷扰,只聊本质。
凭借着 VLM 视觉语言模型,以及云端的训练算力,理想汽车提出了一条由三个环节组成的智能驾驶技术路线:
端到端大模型,负责最主要的智能驾驶任务,按照李想本人 6 月在中国汽车重庆论坛的演讲,这部分是跑在单颗 Orin X 芯片上的。
VLM 视觉语言模型,负责理解环境、跑出驾驶决策建议和轨迹,是端到端大模型的参考,时延(响应速度)相对慢,但理论上思考更拟人。
目前理想的 VLM 有 22 亿个 token,在 Orin X 上时延 0.3 秒,对应着 3.34HZ 的刷新率。
最后是云端训练中心,截止至 8 月,理想汽车已经拥有超过 4.5E 的云端算力,它会对车端推理模型做实时检验,李想本人形容为「考试」。
快-慢-云三种不同时延的智能驾驶数据利用方式,组成了理想汽车的手牌。
三个月后,一直在第一梯队争先的小鹏和智己,也分别打出了自己的新牌。
2. 小鹏特色
10 月 24 号的广州,李力耘表示,目前小鹏汽车的大模型战略,是先将云端大模型做好,然后用蒸馏的方式部署到车端。
四年前,新造车流行一个梗「软件看小鹏」,指的是小鹏汽车在那个硬件普遍贫瘠的年代,通过软件优化的方式实现更优效果——蒸馏这个词,体现了小鹏多年来的软件优化思路。
蒸馏(distillation)来源于热力学,指的是用不同沸点提取出液体内不同成分。
运用在深度学习上,则代表着一个泛化能力更强的大模型,通过知识蒸馏(target-based、feature-based)、量化(Quantification)、参数矩阵近似(Parameter matrix approximation)等等形式,缩小模型参数的同时,也能保证足够高的模型准确率。
我们直接上疗效:深度学习的蒸馏技术,可以让我们用一个更小的模型,在不同的特定任务上,实现类似于更大体积模型的输出能力。
结合当前智能汽车的硬件发展阶段,蒸馏是必需的技术手段之一。
两个已知条件,分别是每一台 XNGP 车型的推理算力,以及何小鹏手里用来买训练卡的预算,接下来小鹏汽车打算做的,是将蒸馏用到极致。
李力耘表示,基于云端大模型打磨车端能力,是小鹏汽车预研端到端的阶段,就已经决定的「制胜关键」。
目前小鹏云端大模型的参数量是车端的 80 倍——考虑到 2025 年 10E 训练算力的规模,云端参数量不算高。
但另一个考虑,是 Orin 时代的小鹏汽车,最高每台车算力被限定在 508T。这样的背景下,加速蒸馏效率,比扩大云端规模更关键。
李力耘也给出了另一个数字:目前小鹏云端大模型的训练效率,已经累计提升了 2.6 倍。
3. 智己的老司机
今天下午,刘涛和曹旭东也透露了一些殊途同归的智驾进步。
比如「长短期记忆」,指的是智己 IM AD 在车端和云端,会采取不同的数据迭代频率和优化方式。像是车端会使用按周迭代的频率,而云端则是按天快速迭代。
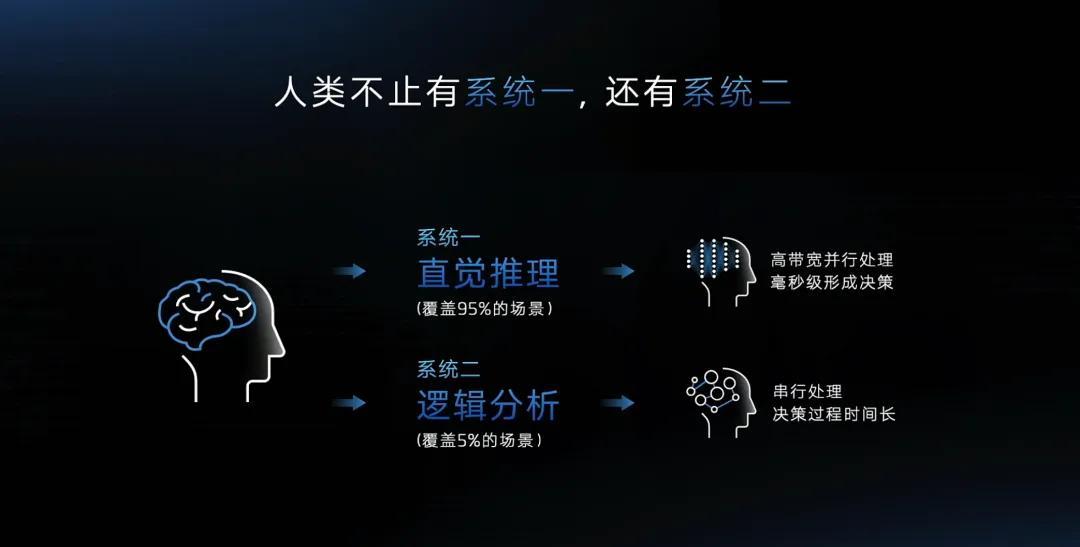
再比如似曾相识的「一二系统结合」。
智己一直在打造老司机的智驾「人设」,而一个优秀的司机,应该做到反应敏捷、决策老练两点。智己和理想的「慢」,都是希望强调智驾系统决策的老练。
刘涛则将他们的快慢,总结为「一段式端到端」+「安全逻辑网络」。
曹旭东透露的数字里面,智己已经实现了模型训练成本的 10-100 倍节约,并且可以实现「边看边开」的超低时延效果,这是快;脱悦则表示一段式端到端,还会将数据交给安全逻辑网络,这是类似老司机的「慢」。
写到这里,我们可以总结 10 月份智驾齐发这三家,背后一部分逻辑。
首先,对 One Model 路线的探索,开始体现收益:时延更低、模型刷新率更高,对应着「直觉」、「快」,等等。
同时,2024 年底,各家数据利用效率跟年初相比,又有了进一步提高,云端训练算力的投资,也更明显地反哺到车端,比如小鹏用云端的 10E 算力,提高车端大模型的上限。
技术创新按部就班,但竞争的压力时不我待。
2023 年 7 月,当时还担任小鹏汽车智能驾驶负责人的吴新宙,说了这样一句话:
「自动驾驶不是一个广告学,是一个非常扎实的工程,需要很大的积累」。
当然后面的故事并没有如吴新宙期盼般发展,智能驾驶的宣传愈发浮躁,智能对汽车购买决策的影响、车企品牌形象传播、智驾实际发展水平,三者即使到了 2024 年,也并没有达到同步的发展阶段。
我们今天提及的三家车企,不约而同地走上了高效利用数据的路线。但回归车辆本身,智驾芯片的迭代以两年甚至三年为周期,硬件底层的变动,其实远远跟不上舆论和用户,对新造车的要求。
比如智驾小视频。
短视频的兴起,让单一长板对消费品的购买决策影响加深。回到智能驾驶,则对应着「丝滑绕行」、「老司机避让」、「无保护左转」等一个个切片。
但天平的另一边,是单一功能短板,也同样会被无限放大,矛和盾的转化,只在于攻防两方的一念之间。
都说造车是带着镣铐起舞,智能驾驶同样严格遵循这条规则。
从 2D 到 3D,从 BEV 到占用网络,从模块化到模块化端到端再到 One Model,智能驾驶的技术演进逐渐匹配摩尔定律,甚至试图跟上短视频时代的传播节奏,但最终仍然受汽车安全法规限制。
这就导致核心的技术演进以年为单位、数据飞轮迭代按周算。但为了跟上传播战场的节奏,车企需要每天一个新词条,每天一次舆论战。
我们听到不同声音的渠道变多了,但问题在于,嘴巴和手是两个器官,说的话和做的事,也代表着两种不同的结果。
希望创新更盛,而不是论战更甚。
(完)
来源:第一电动网
作者:电动星球News蟹老板
本文地址:https://www.d1ev.com/kol/251749
文中图片源自互联网,如有侵权请联系admin#d1ev.com(#替换成@)删除。




先估价再买车,买的放心开的安心
您的询价信息
已经成功提交我们稍后会联系您进行报价!

















 京公网安备
11010502033163号
京公网安备
11010502033163号