2020年,离开地平线的吴强选择自主创业,他认为,存算一体技术是AI芯片的新方向,对于长期被“卡脖子”的国产芯片厂商来说,存算一体芯片可能是国产芯片算力弯道超车的绝佳机会。
同年11月,后摩智能成立,吴强组建了自己的团队,誓要亲身参与这场属于国产阵营与海外阵营的算力大战。

创业,吴强盯准了一个趋势——
国产替代。
在芯片短缺越演越烈的那几年,国产化替代的诉求越来越高,特别是车规级芯片,成了整个产业供应链的刚需,这无疑给国内创业者提供了千载难逢的超车时机。
刚过去的5月10日,后摩智能发布了第一款大算力存算一体智驾芯片鸿途H30,并将智能驾驶作为落地场景。吴强的团队,终于在大算力存算一体芯片领域迎来产品级的发布,当然,这也是国内首款存算一体的智驾芯片。
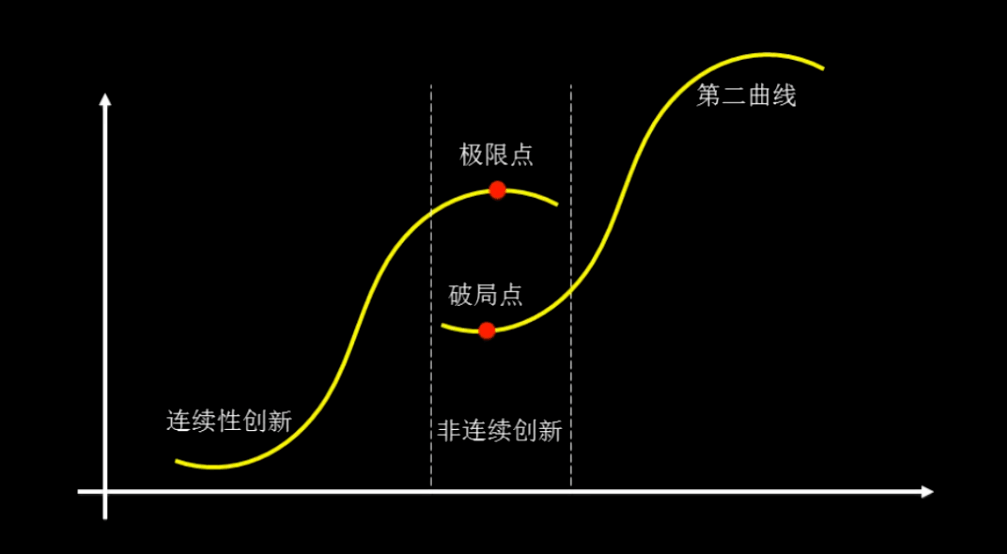
第二成长曲线
经济学里的第一曲线,指的是企业在熟悉环境里开展传统业务所经历的生命周期,第二曲线则是面对新市场、新变革所经历的生命周期。
英国管理学大师查尔斯·汉迪(Charles Handy)用“第二理论”给转型升级传递了相似的思路:为了向前发展,必须在改革中开辟一条完全不同的新道路,对熟悉的问题要有新视角,也就是托马斯·库恩(Thomas Kuhn)所说的“范式转移”。
实际上,每一个行业都将面临经济学里的第二曲线,特别是身处算力军备赛的芯片领域,更是在海量算力需求里经历着第二曲线的突围与探路。
颠覆芯片的底层架构设计,存算一体,正是突破算力瓶颈、摆脱存储宽带限制的一条路径。
关键词之一,是顺势。
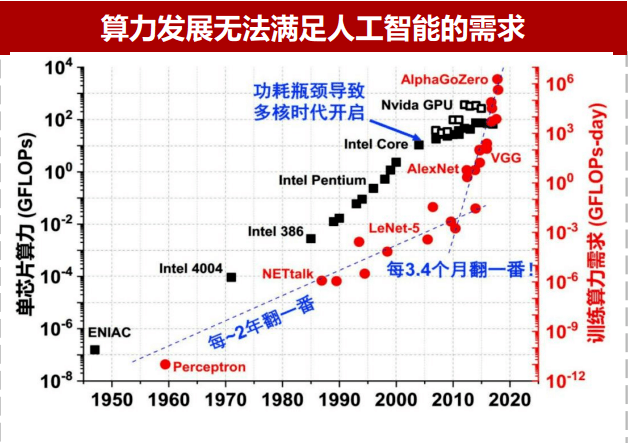
大部分读者都知道,算法、算力和数据是大模型时代的三大基础要素,ChatGPT引爆了算力要求的“核聚变”。当摩尔定律已经被逼近物理极限,如何突破算力瓶颈已成为业界重点突围的方向之一,因为模型计算量的增长速度,已经远超AI硬件算力增长速度。
延伸到智驾领域,当汽车迎来智能化新时代,高级别的自动驾驶对算力有非常严格的需求,特别是到了L4,算力要求已达到1000T以上,且伴随着Corner Case的增加,算法模型增大,更具复杂性,算力的需求也随之攀升。
关键词之二,是破局。
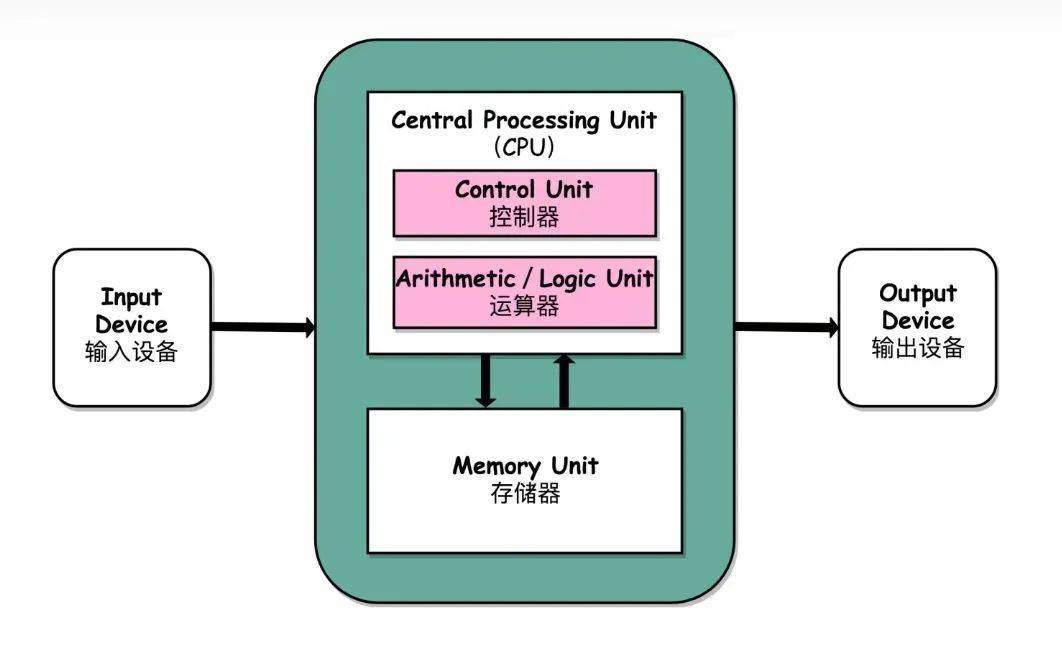
经典的冯诺依曼架构里,数据从处理单元外的存储器提取,处理完之后,再返回存储器。因此,基于冯诺依曼体系结构的算力相对简单,且CPU和存储器之间存在巨大的速度差,抵达一定的极限后,存储器就很难跟上运算部件消耗的数据了。
量产阶段的困局体现在:
(参考:《量子位·存算一体芯片报告》)
-即使芯片制程更加先进了,但对于制造商来说还是投入产出比极低,研发与生产成本上去了,性能提升却往往不如人意。
-集成电路尺寸进一步缩小,芯片的可靠性也受到挑战,诸如由“短沟道效应”和“量子隧穿效应”等引发的芯片漏电。
-先进工艺下尽管芯片拥有大算力,但同时也产生了高能耗,对于功耗敏感的应用场景,先进制程不占优势。

因此,芯片行业一直有这样一种说法,冯诺依曼的架构思路既是一切现代计算机的基础,又是现代计算机难以绕开的桎梏。如何解开这层与生俱来的桎梏,突破计算单元与存储单元分离的缺点,成为很多芯片玩家努力的方向。
何为存算一体?
字面上来说,作为一种全新的计算架构,存算一体是在存储器中嵌入计算能力,将存储单元和计算单元合为一体,省去了计算过程中数据搬运环节,消除了由于数据搬运带来的功耗和延迟,提升计算能效。
在吴强看来,将公司首款存算一体芯片应用于智驾,是一个非常漂亮的决定。
因为在技术和产品匹配的角度,这颗芯片带来的优势,和自动驾驶的关键需求是天然吻合的,可实现极致能效比和超低延时,让底层的芯片更好地扮演着人类大脑的角色。

一个,是打破存储墙。
面对存储墙、带宽墙和功耗墙等挑战,存算一体芯片能成百上千倍地提高计算效率,从而降低成本,消除不必要的数据搬移延迟和功耗,这也是较多核并行加速技术更为颠覆的地方。
另一个,是算力与能效。
计算直接在存储器内完成,可提供大于1000TOPS以上的算力和超10-100TOPS/W的能效。通俗一点讲,就是在面积不变的基础上,翻倍增加计算核心数,数据层面,成几何式提升。
256TOPS & 35W
昨日,后摩智能正式发布了旗下首款存算一体智驾芯片——鸿途™H30,最高物理算力达到256TOPS,典型功耗35W,这也意味着,国内科技公司自研资产的存算一体大算力AI芯片,终于在智驾领域落地了。
“是物理算力,不是稀疏虚拟算力。”
吴强手里拿着一颗H30,向大家介绍该芯片的核心指标。他特意强调,256TOPS是物理算力,并不是大家平日里提及的稀疏虚拟算力,这也意味着,H30目前创造了国内之“最”,即国产智驾芯片里物理算力最大的产品。
有种“一览众山小”的俯视感,且值得一提的是,弄出这样一颗芯片,后摩智能只用了短短两年的时间。

优势不止于此。
256TOPS的算力,功耗只需要35W,这也意味着,其能效的数据更是“吊打”一众国内的智驾芯片产品。
地平线CEO余凯曾感慨,尤其是在智驾芯片领域,属于寡头性非常强的领域,到后来,大部分玩家都会陪跑,最终能跑出来的公司屈指可数。虽然我们看不清赛道的终局,但从目前来看,作为只有两岁的创业公司,后摩时代的成绩是可圈可点的。
还有一些数据参数:
性能指标——
后摩智能用H30与英伟达的产品相比,在Resnet50下,前者Batch=8达到10300帧/秒的性能,是后者的2.3倍;而在Batch =1时,前者性能达到8700帧/秒,后者仅为1520帧/秒,是英伟达的5.7倍。

计算效率——
H30在上述相同的比较维度,Batch = 8的情况下,计算效率达到294FPS/Watt,是英伟达的4.6倍,Batch=1时,这一数字更是高达11.3 倍。
这里还有一个细节。
吴强曾在一次交流中表示,存算一体是架构的创新,而工艺则是另一个维度的事情。好工艺肯定是好事,后摩智能也在用先进工艺,但是对存算一体来说,对先进工艺依赖度其实是比较低的。
事实确实如此。
而且,这正是后摩智能的优势所在。H30是基于12nm工艺制作的,但是英伟达的却是8nm,这也可以看出,如若两家公司的产品工艺处于同样的节点,来自后摩智能的产品势必效率更高。

后摩强调的,是架构。
决定H30拥有上述优秀数据的核心,是后摩智能面向智能驾驶场景自主研发的第一代IPU(Intelligence Processing Unit)——天枢架构。
它是新产品拥有超越同级性能的“幕后功臣”在它的指导下,H30提升了两倍性能,功耗降低了约50%。
演讲台上的吴强用了这样的比喻:
特斯拉的FSD,是堆积计算,就像一个四合院子,房子的主人最大限度地利用了面积,堆放了日常用品,且房屋构造利用率极高,但尽管如此,这里的面积还是有限,想无限扩大社交范围,非常困难。

后摩智能则不同,它是中式庭院和西式高楼的组合,同样是四合院大小的面积,通过西式高楼,不同楼层有自己的公布布局,且高楼内部协调性极佳,就像一个综合办公楼,大家可以在最小的用地面积上实现最大范围的社交功能。
落地元年
吴强曾在此前的中国电动汽车百人会论坛上预测,2023年将是国内存算一体智驾芯片商业落地的元年,如今,他用自己率先落地的H30,打响了细分赛道鸣枪开赛的第一声。
《NE时代》翻看了吴强此前在公开场合提及的产品研发心路,在存算一体高算力芯片落地的过程中,他和团队也经历了诸多困难。
一如,散热。
存算一体,除了大算力的需求,汽车智能化和电动化又带来了功耗、散热、成本和自主可控等难题。
他的团队确实在其中克服了很多障碍,比如说,如何在大算力的同时又能做到低功耗,保证自然散热。他希望用存算一体的架构在做到自然散热的情况下,可以做到算力2-3倍的提升,这是存算一体赋予的能力。

二如,存储介质。
从产业链的角度来说,存算一体依赖于存储介质工艺,后摩智能目前的产品是基于SRAM,下一代产品则计划基于其它一些存储机制,例如MRAM和RRAM。
其中,存储工艺又依赖于上游厂商,如台积电这样的公司,但目前RRAM在台积电的成熟度属于风险等级,距离完全量产大约有1-2年时间。这是产业链的依赖,虽然有风险,但不得不经历。
三如,技术转移。
存算一体,之前很长一段时间,业界几乎是以学术研究的方式在做,但从学术到商业量产还有一定距离。
后摩智能和其他一些创业企业,更多是按照商业量产的标准去做,过去两年都在不断探索中试错。比如,具体怎么做量产,怎么做DFT(Design for Test,即可靠性设计),怎么做冗余,怎么做自修复,这些都是公司要解决的问题。

四如,验证与磨合。
CPU、GPU和AI芯片等“大芯片”赛道,从创业的角度看,这类芯片烧钱多、周期长,很难快速上量,但是技术壁垒更高、增长空间更大,且客户黏性强。
做出原型验证芯片之后,公司还有很多工作,就智能驾驶芯片来看,进入汽车产业的配套环节,也需要较长的验证与磨合周期。

他曾在接受媒体交流时表示,创业初期,他自己曾经也迷惑过。因为看到一些创业企业还没量产,就开始有资本运作筹备上市,这样的信号,他会怀疑自己,这种从底层技术产品开始的创业方式是不是太保守了——
半导体是一个需要技术沉淀和积累的行业,跳来跳去,怎么能有真正的技术积累和能力提升?
事实说明,他的怀疑和自省都是对的,而对于两岁的后摩智能来说,率先落地第一颗存算一体智驾芯片,也只是万里长征的第一步。毕竟,大家都看到了趋势,被时代裹挟着向前,对手们也没有闲着。
来源:第一电动网
作者:NE时代
本文地址:https://www.d1ev.com/kol/202635
文中图片源自互联网,如有侵权请联系admin#d1ev.com(#替换成@)删除。




先估价再买车,买的放心开的安心
您的询价信息
已经成功提交我们稍后会联系您进行报价!







 京公网安备
11010502033163号
京公网安备
11010502033163号