2019 年的上海车展上,一辆纯电轿跑吸引了参会者的注意。
溜背式造型、修长车身、无框车门……各种新奇的设计瞬间抓住了所有人的眼球。
是的,这就是小鹏 P7 新品首发时的一幕。
不过,这辆车的看点并不止于此,其智能化水平更值得关注。
尤其是装载在小鹏 P7 上,号称首次在国内上车的那颗英伟达 Xavier 芯片,引起了人们的兴趣。
甚至有网友专门为了了解小鹏 P7 用了什么芯片,来到车展现场。事后,他第一时间在网上分享了这一信息。
在 Xavier 芯片的加持下,小鹏 P7 实现了高速场景下的上下匝道、低速场景下的自动泊车及代客泊车等功能,由此在造车新势力中率先赢得了「智能化」的标签。
在一颗芯片上同时集成了「行车+泊车」功能,这正是现在聊得火热的「行泊一体」,小鹏 P7 打响了第一枪。
而后,理想 One 2021 款、上汽第三代荣威 RX5、2023 款 KiWi EV 大疆版等也基于不同的方案上马「行泊一体」功能,发展到现在,更多车型加入进来。
从供应商的角度来看,现阶段至少有 20 家自动驾驶企业发布了支持行泊一体的智能驾驶方案,大部分将于今明两年量产落地。
汽车之心在《众口不一的行泊一体,终于被说清楚了》一文中,从 Nullmax 纽劢等算法研发企业的视角,讨论了行泊一体在软件层面上的具体实现路径。
事实上,行泊一体与芯片的关系更为直接。
芯片作为算法的载体,扮演着更基础的角色。甚至从某种角度来说,芯片的选型决定了行泊一体的大部分表现。
01、芯片厂商,行泊一体背后的隐秘玩家
按照业内普遍的说法,行泊一体要实现的是传感器深度复用和计算资源共享,而这些均与芯片的架构有关。
过去在行泊分离的情况下,行车功能只能调用行车的芯片和传感器,比如前视相机、毫米波雷达,而泊车功能也只能调用泊车的芯片和传感器,比如鱼眼相机、超声波雷达。
现在要做到行泊一体,即行车时能调用鱼眼相机,在拥堵跟车、cut-in 等情况下提高车辆通过率,泊车时调用前视摄像头,提升车辆前向的感知能力,识别路上的障碍物。
这些意味着在单颗 SoC 上需预留足够多的传感器接口,包括多路摄像头接入、多路以太网设备接入(激光雷达和 4D 毫米波雷达的主要接口)、多路 CAN 接口设备接入(3D 毫米波雷达的接口)。
芯片内部的异构类型也要进行相应设计。
例如,行车场景下,摄像头和毫米波雷达的数据融合以及地图定位需有足够算力的 CPU 以及 DSP 去完成,而泊车场景下,3D 环视全景的渲染和图像拼接都必须使用 GPU 来完成。
也就是说,面向行泊一体功能设计的 SoC 芯片,基本都要同时集成 ISP、GPU、MCU、CPU、DSP 等处理器单元。
黑芝麻智能产品总监王治中进一步介绍:
「CPU 资源用作多任务的调度以及多传感器融合等工作,ISP则对于多路摄像头输出的 RAW 图像信号进行调校,而 DSP 配合 AI 加速器可以释放一大部分 ARM 的资源。」
其中,又以 GPU 为代表的 AI 加速器为芯片的核心,承担了大规模浮点数并行计算需求。
业内常提及的的某芯片算力是多少 TOPS,指的就是这类芯片的 AI 核心在进行卷积神经网络计算中,以卷积和输入矩阵的乘加运算的速度作为参考而计算出来的一个理论值。
根据搭载芯片算力的大小,分野出轻量级行泊一体方案(算力在 20 TOPS 上下),和高阶版行泊一体方案(超过 100 TOPS 且无上限)。
二者的区别在于支持的传感器配置和数量,以及运行的神经网络模型复杂度不同,进而导致使用场景和体验的差异。
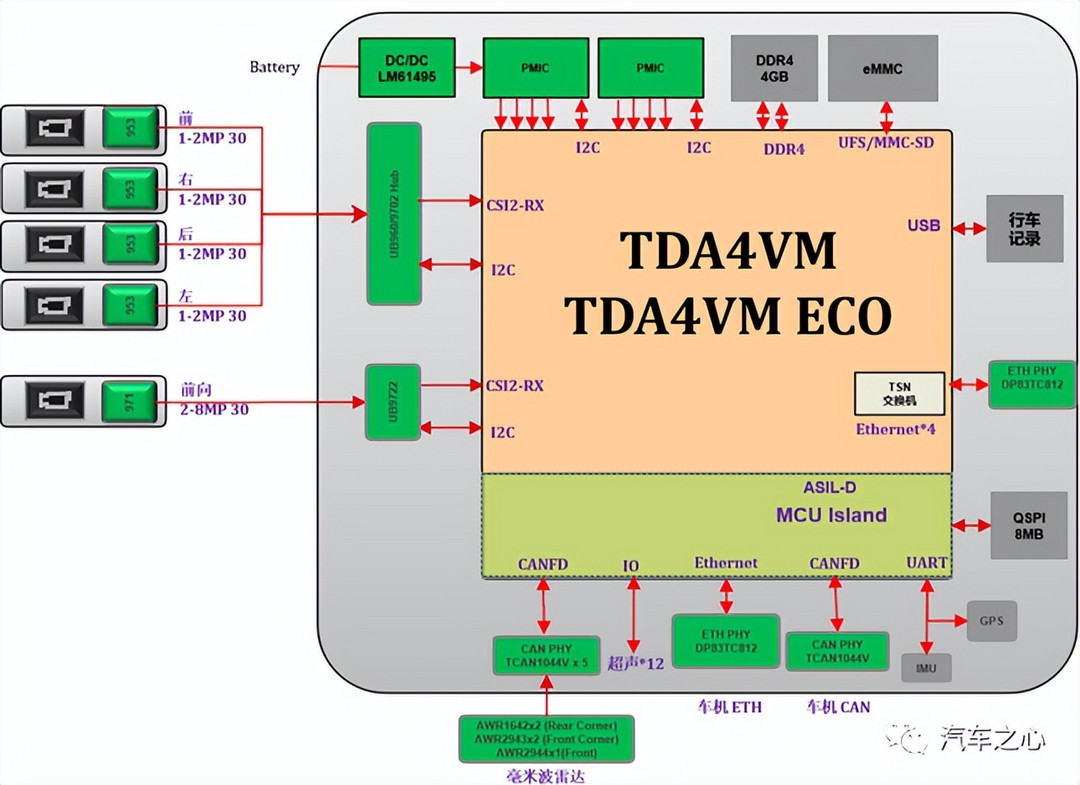
例如,Nullmax 基于 TI 单 TDA4VM 芯片的行泊一体方案,采用 2 颗前视摄像头、4 颗鱼眼摄像头、5 颗毫米波雷达、12 颗超声波雷达的传感器配置,在 8 TOPS 的 AI 算力下,实现领航辅助、高速代驾辅助、拥堵跟车辅助、记忆泊车等一系列的行车、泊车功能。
而基于英伟达标准版 Orin(110 TOPS)芯片,搭载更丰富的传感器,Nullmax 除了能实现上述所有功能,还提供像特斯拉 FSD 一样能够在城区道路等场景下运行的智能驾驶体验,且不依赖高精地图。
由于面向数量更为庞大的中低端车型,轻量级行泊一体拥有更广大的市场,这也是芯片厂商诸如 TI、黑芝麻、地平线、寒武纪行歌等的必争之地,代表产品分别为 TDA4(8 TOPS)、A1000L(16TOPS)、J3(5TOPS)、SD5223(最大算力超过 16TOPS)。
其中,TDA4 算得上「当红炸子鸡」。
有数据统计,目前国内 10~20 万价格区间搭载行泊一体方案的车型中,部署 TDA4 的车型占到了 40%-50%。
包括前文提到的 Nullmax,还有百度、大疆、MAXIEYE 等众多的自动驾驶解决方案公司,都在基于 TDA4 芯片开发行泊一体方案。
黑芝麻 A1000L 和地平线 J3 势头也很猛,基于单颗 A1000L 、「J3+TDA4VM」、双「J3」、三「J3」的自动驾驶方案也在陆陆续续上车。
寒武纪 SD5223 今年即将发布,面向 L2+级自动驾驶市场,支持自动驾驶系统向 10 万元左右的入门级车型覆盖。
高阶版行泊一体也在迎来大爆发。
英伟达 Orin-X、黑芝麻 A1000/A1000Pro/ A2000、地平线 J5 等都在瞄准了这一市场,例如 2 颗英伟达 Orin-X 芯片「上线」理想 L9,以总计 508TOPS 的算力,支持自动泊车、城市智能驾驶、远程召唤、OTA 升级等场景和功能。
2022 年 9 月底,理想 L8 发布,地平线 J5 全球首发在该车型上。
再往前,2022 年 4 月,地平线与比亚迪达成定点合作,地平线 J5 将搭载在比亚迪部分车型上,以打造拥有高等级自动驾驶功能的行泊一体方案。
同样的,黑芝麻华山二号 A1000 系列芯片已经拿下了江汽集团、吉利等车企行泊一体项目的量产定点。
02、一颗合适芯片,需要性能、功耗和成本的平衡术
分析各家厂商的产品布局,我们得以一窥行泊一体究竟需要一颗怎样的芯片。
首先,对于轻量级行泊一体,芯片需要平衡好性能、功耗和成本三者之间的关系。
从性能上来说,影响的主要因素在于 SoC 异构多核的设计,至于每个核的能力有多强,因芯片厂商而异。
「比如,有的 SoC 芯片内部只有 1 个或 2 个 DSP,DSP 可能全部被分配去做传统的 CV 图像处理,而黑芝麻芯片的内部有 4 个大型 DSP,这些 DSP 除了做大量图像及激光算法处理之外,还承担实时管理神经网络加速器的工作,大大释放了 CPU 资源。」黑芝麻智能高级产品经理额日特介绍道。
同理还有 TDA4,正是因其设计优异,受到众多方案商们的青睐。
它采用了多核异构的结构,配有包括 Cortex A72、Cortex R5F、DSP、MMA 等在内的不同类型处理器,由对应的核或者加速器处理不同的任务,如逻辑算力和 AI 算力,效率更高。
地平线 J5 也专门在芯片设计阶段,对架构需要的底层单元逻辑进行了整体布局,首先将复杂的计算拆解成几个小的、可并行的计算,同时还可将过去需要串行处理的指令集,通过编译器的分析,拆解成若干个并行化的流水线模式,从而降低计算延时,提高效率。
在被地平线称为「贝叶斯」的计算架构下,J5 芯片可以在多路数据的大量吞吐能力下,仍然可以保持稳定、高效地数据处理。
功耗也是攸关芯片表现的重要指标,并直接关系到成本。
有人直言,功耗是芯片设计企业最大的挑战。背后原因在于,如果功率过高,会引起芯片温度升高,进而降低其可靠性。
以某芯片为例,最高功耗达到 20W,这给方案商带来巨大麻烦,导致要么不选择该芯片,要么想办法解决散热问题。
「例如引入液冷装置,不过这会造成更高的系统复杂度,并引起成本上升。」一位业内人士指出。
针对于此,寒武纪行歌提出采用高能耗比的 AI 架构,可获得比传统 GPGPU(通用图形处理器)架构更高的性能和更低的功耗,并采用自然散热,有效解决了成本增加的问题。
不过,芯片的综合成本仍亟待相关厂商进一步压缩。毕竟将轻量级行泊一体上车的主机厂本就是对成本比较敏感的群体,其对芯片的要求不仅要性能好、功耗低,价格还要有优势。
对于高阶版行泊一体,最基本当然是算力要足够高,安霸软件研发高级总监孙鲁毅表示,CPU 算力至少要达到 150KDMIPS,AI 算力至少 100TOPS。
这是由于高阶版的行泊一体方案需要接入更多路、更高分辨率的摄像头,还要增加 4D 毫米波雷达、激光雷达等传感器,并且运行的神经网络模型也要更大更复杂,因此 CPU 算力和 AI 算力需求都会呈 7~10 倍的增长。
此外,由于智能汽车还在不断进化,需要预埋高算力芯片,以适应后期的 OTA 功能更新。
不过算力并非越高越好。
最近芯片厂商貌似开启了算力大战,典型如英伟达甩出 2000TOPS 算力的自动驾驶芯片 Thor「王炸」后,高通立马跟进推出 Ride Flex Premium SoC,加上外挂的 AI 加速器,其综合 AI 算力也能够达到 2000TOPS。
实际上,对于行泊一体来说,并不需要如此高的算力,更重要的指标是芯片利用率。
业内经常吐槽,英伟达 Xavier、Orin 的利用率基本上都维持在 30%,造成了算力的巨大浪费。
而高通的自动驾驶芯片和 Mobileye、华为以及国内的主控芯片创业公司走的是 ASIC 路线,利用率均优于英伟达的 GPU 方案。
功耗仍是高阶版行泊一体十分关注的点,芯片厂商们仍在想办法降低这一数值,最直接的方法便是改进芯片制程,从 6nm、12nm 迈向 7nm。
2022 年 1 月,高通透露其骁龙 Ride SoC 将以 5nm 制程打造,成为业内首款 5nm 制程自动驾驶芯片。
相比之下,成本不再显得那么重要。
采用大算力芯片的车型,往往在定位偏高端,例如理想 L9(双 Orin-X 芯片)、小鹏 G9(双 Orin-X 芯片)、蔚来 ET7(四颗 Orin-X 芯片)、WEY 摩卡(单颗 360TOPS 算力的骁龙 Ride 芯片)等等,对于芯片价格的敏感度远低于应用轻量级行泊一体的车企。
03、芯片厂商开启角逐战,2025 年之前上车是关键
行泊一体功能的实现牵涉到芯片厂商、算法企业、域控制器、主机厂等一整条产业链上的参与者。
这意味着,处在最前面的芯片厂商不仅需要打磨好硬件产品,做好后方的顺利「交接」也十分重要。
有域控制器厂商曾吐槽,当前芯片较为复杂,功能也较多,行业对于 SOC 端基础软件平台产品尚无完整的普适性标准,导致其方案在不同平台之间的移植时,复用性不高。
对此,黑芝麻 A1000L 和 A1000 采用 pin2pin 的平台化方案设计,在相同的软硬件架构下,算力可以灵活配置,降低了域控平台的拓展升级成本。
此外,芯片厂商如果能提供配套的工具链、软件栈等,将更有助于下游对于行泊一体功能的开发。
TI 的 TDA4 备受追捧的原因之一在于其工具链比较成熟,相关厂商在此基础上做二次开发更容易。
英伟达也推出了 NVIDIA DRIVE 开源软件堆栈,拥有完善的工具链和丰富的算子库;地平线的 AI 开放平台 - 天工开物也包含 AI 芯片工具链和 AI 应用开发中间件,还有模型仓库;黑芝麻发布了瀚海 ADSP 自动驾驶中间件平台;
而高通表示,Snapdragon Ride 平台不仅包括硬件,还将为芯片提供「安全中间件、操作系统和驱动程序」;寒武纪行歌在今明两年将推出多款自动驾驶 SoC 芯片,并提供成熟的软件工具链。
芯片企业在自动驾驶产业链中变得更加活跃,现在芯片企业会直接去面对主机厂,帮助 Tier1 拿项目,或者直接和主机厂展开合作。
通过这种形式,芯片公司不仅可以直接向主机厂展示其芯片的一些能力,还能够直接获取主机厂的一些诉求,比如域控制器后续的可拓展性要求、芯片的接口、计算资源等需求,从而能够更及时地去调整他们的产品战略方向。
如今芯片企业在自动驾驶产业链中的地位日益提升,尤其是大算力厂商直接面对主机厂展开合作。
一般而言,双方会就行泊一体功能进行联合开发,例如芯片厂商给予「硬件+开发工具」支持,车企在基础上自研上层算法,不过也有主机厂为了尽快将行泊一体量产上车,要求提供软硬一体的打包解决方案。
而这就需要芯片厂商还具备从硬件到算法的「全家桶」能力。
高通公司发言人就明确表态:
「对于一部分汽车制造商来说,如果软件开发能力较弱,并且第三方传统 Tier1 供应商开发成本过高,我们可以直接提供完整的 ADAS 交钥匙方案。」
除了算法能力,芯片厂商其他的「软实力」也十分重要。
例如产品的一致性、可靠性,以及供应链保供能力,这些正是 TI 等老牌企业的强项。
TI 在车规级芯片供应的传统供应商里,有着绝对的研发经验,其芯片可靠性长期被验证过,车企比较信任。
在供货方面,此前主机厂或域控 Tier1 都遭遇了英飞凌等 MCU 大厂的缺货,造成巨大损失,而 TI 的 TDA4 VM 芯片中内置了 MCU 核心,让他们免去了对车规 MCU 保供的担忧。
可以看到,行泊一体带来的是芯片厂商全方位能力的比拼,随着主机厂先后官宣上车,这种比拼越发进入白热化阶段。
据不完全统计,现阶段至少有 20 家自动驾驶企业发布了支持行泊一体的智能驾驶方案,大部分将于今明两年量产落地。
「主 SOC 决定了车企新一代智驾平台的硬件架构、软件架构、算法体系,一旦选定,车企非必要不会进行切换。」
业内人士表示,主机厂培养成熟供应商的成本极高,这也就导致了芯片厂商在现阶段就开启了「内卷」。
在黑芝麻看来,2025 年对于国内自动驾驶芯片玩家或是关键时点,在之后国产供应链体系将搭建完毕,「每个坑都会开始有萝卜了」。
目前,黑芝麻 A1000、地平线 J5 与英伟达 Orin 正在争夺量产上车,寒武纪行歌 SD5226 也将很快亮相,伴随着竞争的加剧,留给其他芯片厂商的窗口期已然不多了。
参考资料 :
1、《单 SoC 芯片方案,或将加速行泊一体方案规模化量产应用》,九章智驾
https://mp.weixin.qq.com/s/fvKZelLpcQAo7ByAqzeF0Q
2、《行泊一体 - 打通智能驾驶的「任督二脉」》,九章智驾
https://mp.weixin.qq.com/s/PINnopqMj2KDV9tGEUY83Q
来源:第一电动网
作者:汽车之心
本文地址:https://www.d1ev.com/kol/189912
文中图片源自互联网,如有侵权请联系admin#d1ev.com(#替换成@)删除。




先估价再买车,买的放心开的安心
您的询价信息
已经成功提交我们稍后会联系您进行报价!














 京公网安备
11010502033163号
京公网安备
11010502033163号