作者 / 周彦武(业内资深专家)
编辑 / 极客之心101
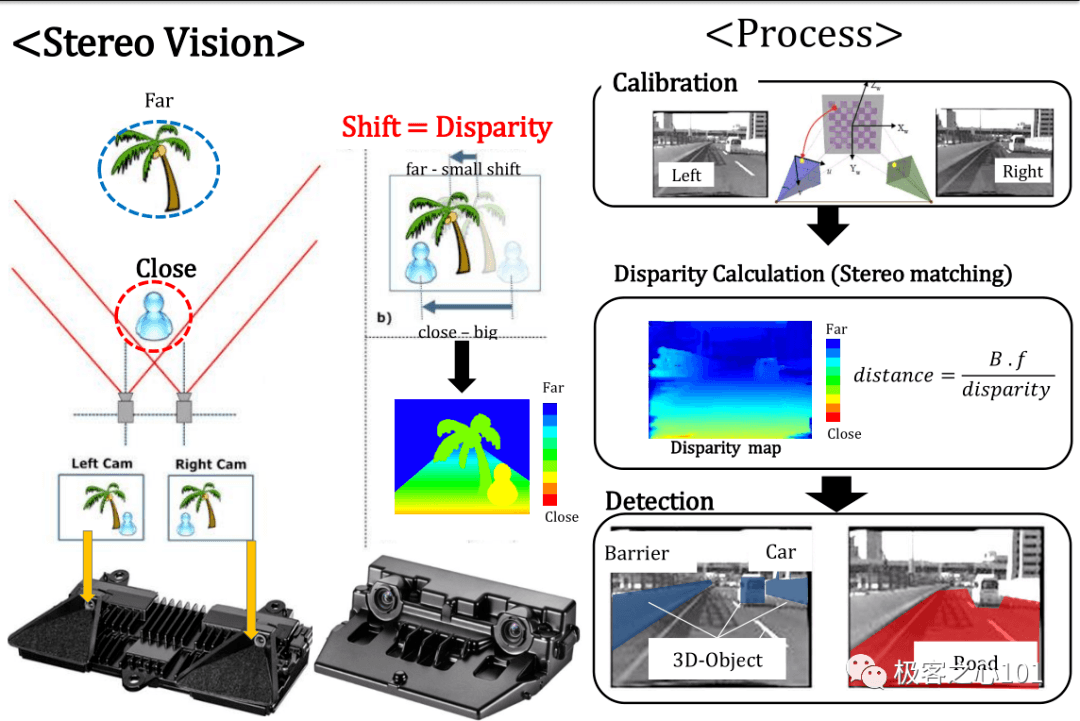
以特斯拉为代表的单目和三目系统,对深度学习高度依赖。
在深度学习视觉感知中,目标分类与探测(detection) 是一体的,无法分割。
这就意味着,如果自动驾驶系统无法将目标进行分类,也就无法进行探测识别。这带来的结果是,车辆在行驶过程中,遇到前方有障碍物时候,会识别为无障碍物,进而不减速直接撞上去。
训练数据集无法完全覆盖真实世界的全部目标,能覆盖 10% 都已经十分了不起了,更何况真实世界每时每刻都在产生着新的不规则目标。
特斯拉多次事故都是如此,比如在中国两次在高速公路上追尾扫地车(第一次致人死亡),在美国多次追尾消防车。还有无法识别车辆侧面(大部分数据集都只采集车辆尾部图像没有车辆侧面图像)以及无法识别比较小的目标。
毫米波雷达容易误判,特别是静止目标,如金属井盖,金属天桥,金属护栏,因此毫米波雷达会自动过滤到静止目标。
此时,自动驾驶系统需要双目或激光雷达,这两类传感器都无需分类即可探测。
那么特斯拉为何不用激光雷达?真的如马斯克所言「激光雷达价格昂贵,丑陋且不必要」吗?背后的真正原因是什么?
01、从激光雷达算法说开去
目前,主流的激光雷达算法也是基于深度学习,深度学习视觉遇到的问题,激光雷达也可能会遇到。
盘点一下,主流的激光雷达算法经历了三个阶段:
第一阶段是 PointNet
第二阶段是 Voxel
第三阶段是 PointPillar
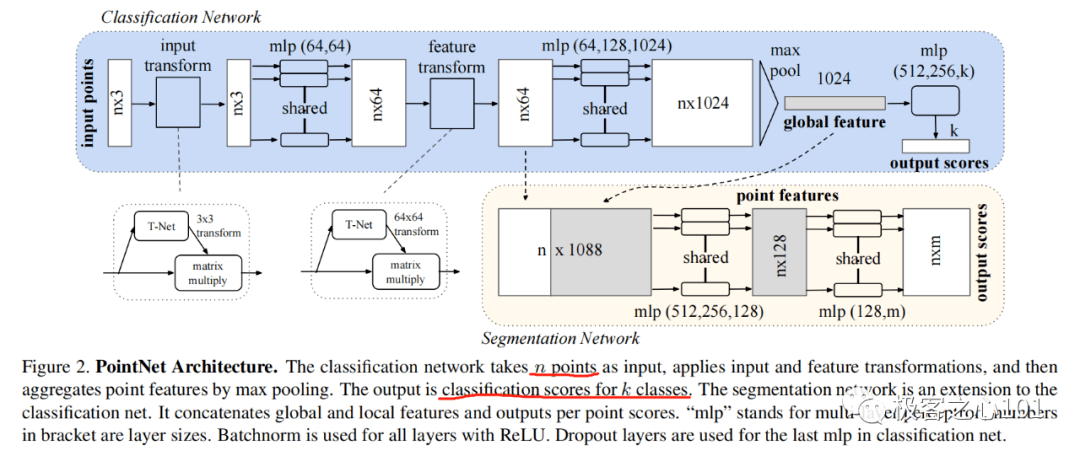
PointNet 是斯垣福大学在 2016 年提出的一种点云分类/分割深度学习框架,是开天辟地的点云深度学习框架。
众所周知,点云在分类或分割时存在空间关系不规则的特点,因此不能直接将已有的图像分类分割框架套用到点云上,也因此在点云领域产生了许多基于将点云体素化(格网化)的深度学习框架,取得了很好的效果。
但是,将点云体素化势必会改变点云数据的原始特征,造成不必要的数据损失,并且额外增加了工作量,而 PointNet 采用了原始点云的输入方式,最大限度地保留了点云的空间特征,并在最终的测试中取得了很好的效果。
有多好呢?
在 KITTI 三维目标检测中,F-PointNet 排名第一,这比激光雷达与摄像头融合的 MV3D 还要好。
PointNet 架构
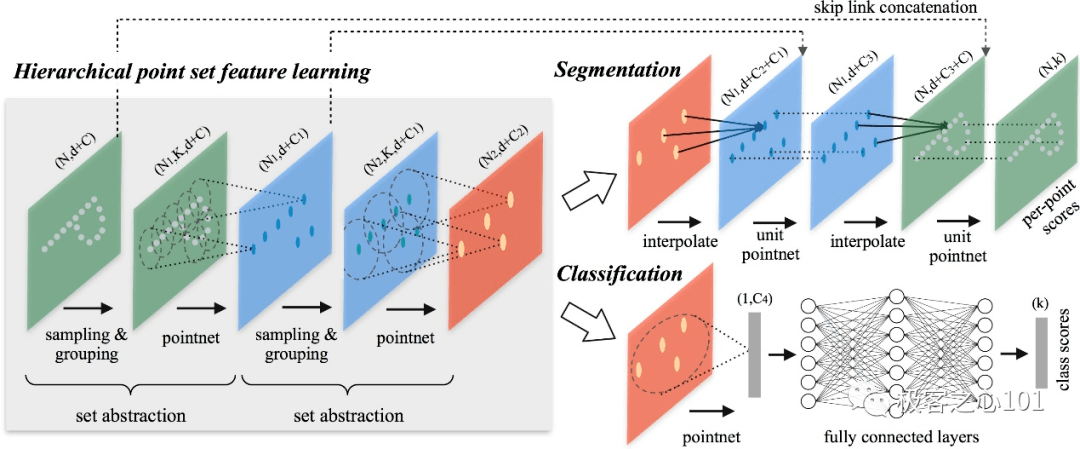
2017 年,斯坦福大学对此做了改进,提出 PointNet++架构。
首先,PointNet 是逐点 point-wise MLP,仅仅是对每个点表征,对局部结构信息整合能力太弱 --> PointNet++的改进:采样(sampling)和分组整合( grouping )局部邻域。
其次,全局特征(Global Feature)直接由最大池化(Max Pooling)获得,无论是对分类还是对分割任务,都会造成巨大的信息损失 --> PointNet++的改进:
分级特征学习框架(hierarchical feature learning framework),通过多个抽样化( set abstraction )逐级降采样,获得不同规模不同层次的局部到全局的特征。
最后,分割任务的全局特征是直接复制与本地特征拼接,生成 discriminative feature 能力有限 --> PointNet++的改进:
分割任务设计了编解码 encoder-decoder 结构,先降采样再上采样,使用跳过连接 skip connection 将对应层的 local-global feature 拼接。
PointNet++结构
但是 PointNet 的缺点是不是端到端的处理方式,处理点云需要大量手工作业,于是 VoxelNet 出现了。
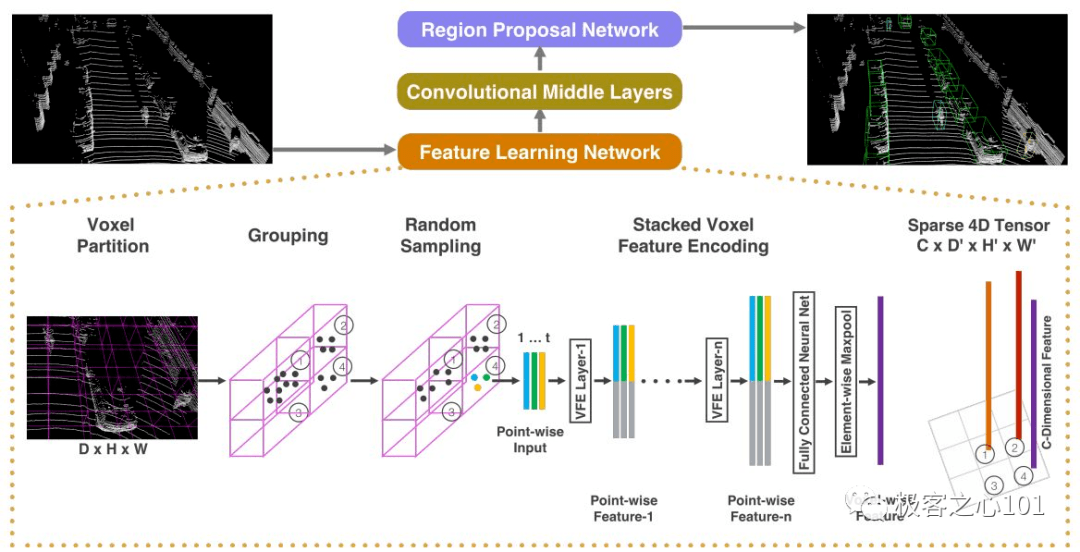
2017年,苹果推出基于点云的 3D 物体检测论文《VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection》:
将三维点云划分为一定数量的 Voxel,经过点的随机采样以及归一化后,对每一个非空 Voxel 使用若干个 VFE(Voxel Feature Encoding) 层进行局部特征提取,得到 Voxel-wise Feature,然后经过 3D Convolutional Middle Layers 进一步抽象特征(增大感受野并学习几何空间表示),最后使用 RPN(Region Proposal Network) 对物体进行分类检测与位置回归。
Voxel 架构
Voxel 的缺点是对 GPU 要求太高,太慢,用3080 这样的 GPU 帧率不到 5Hz。
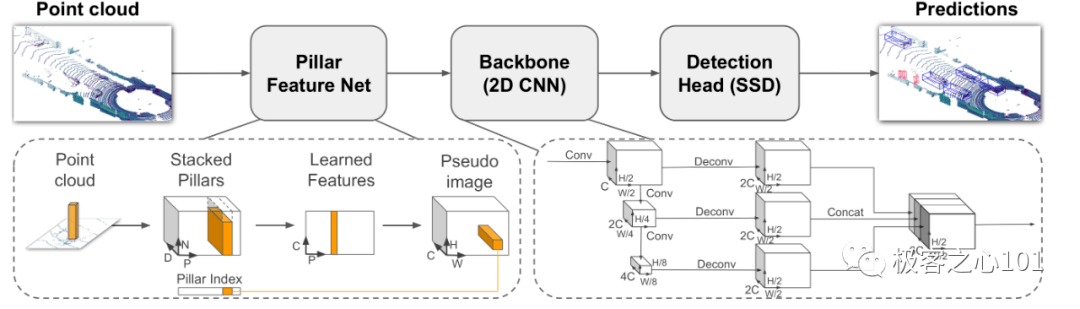
于是终极算法登场,这就是PointPillar,帧率达到 105Hz。
在 VoxelNet 当中,会将所有的点云切割成一个一个 Grid,我们称之称为 Voxel。
PointPillar 也是这样的操作原理,但是在 z 轴上它不进行切割,相当于精简版本的 Voxel,也可以看成 z 轴上的 Voxel 合成一个 Pillar。
这是由知名的零部件供应商安波福提出的算法,是国内车厂用的最多的算法,也是最贴近实战的算法,而不是试验室产品。
PointPillar 少了 Z 轴切割,而是使用 2D 骨干,这导致其精度下降,性能相较于纯 2D 的视觉,提升并不明显,特斯拉不用激光雷达很正常,而不依赖深度学习的具备可解释性的激光雷达算法目前还未见到。
02、自动驾驶的关键问题:过于依赖深度神经网络
深度学习有多好用呢?
不到半年,一个普通大学生就可以熟练调参了,几乎没有人研究激光雷达的传统算法。
目前自动驾驶最关键的问题是,过于依赖不具备解释性的深度学习或者说深度神经网络,这点可能导致自动驾驶永远无法实现。
在没有高浮点算力的 GPU 出现之前,神经网络或者说深度学习可以说完全被否定,英伟达凭一己之力撑起了半边天。
如今 AI 是最热门的话题,最热门的学习方向和就业岗位,如今神经网络已经是 AI 的全部。
实际上,当年加州大学伯克利分校计算机科学家,人类兼容人工智能中心(CHAI)主任斯图尔特·罗素(Stuart Russell)所著作的《人工智能:一种现代的方法》(Artificial Intelligence: A Modern Approach)一书,也只有 4 页左右的内容提到神经网络。
然而对于自动驾驶系统而言,需要一个可解释性。
可解释性,是指人(包括机器学习中的非专家)能够理解模型在其决策过程中所做出的选择(怎么决策,为什么决策和决策了什么)。
因为它和安全强关联,只有具备可解释性才能保证安全性不断提高,如果出了事故找不到人类思维可以理解的原因,那自然就无法解决事故,类似的事故还会发生。
而神经网络或者说现在的人工智能最缺的就是可解释性。
深度神经网络缺乏归纳偏置(Inductive bias),它对未知情况的预测很不确定也不好解释,这导致了使用深度模型时的「黑盒」困扰。
如果是线性回归做拟合,我们可以观测其 Y 值与以 X 向量为参数的线性函数。
如果是 Logistic 回归,我们可以观察其超平面对正负样本的切分情况。
这些归纳偏置都可以证实(justify)模型的预测。
而深度神经网络只能表明 Y 是 X 向量的某种非线性函数,该函数与数据增强、网络结构、激活函数、归一化等各种在训练过程中加入的约束条件有关,这导致在实际使用中无法证实预测结果的有效性。
简单地说,就是特斯拉搞了个算法,它无法预测在某个环境下识别目标的准确度,完全是听天由命,为什么在某个场景下能识别,换了一个场景就无法识别,无法解释。
康奈尔大学发布的这篇论文:《Practical Black-Box Attacks against Machine Learning》(https://arxiv.org/abs/1602.02697v4),提出了一种解决机器学习模型黑盒对抗攻击问题的新思路。
在计算机视觉领域,对抗攻击(adversarial attack)旨在通过向图片中添加人眼无法感知的噪音以欺骗诸如图像分类、目标识别等机器学习模型。
如下图所示,输入原图像,图像分类器给出的结果为「是熊猫的概率为 57.7%」,而在给原图像加上一段噪音后,结果变成了「是长臂猿的概率为 99.3%」。
对于人类来说,这两张图片几乎是一模一样的。
但在人类看来,这两张图几乎没有任何区别。
这是人为设计的噪音,而智能驾驶领域噪音再是非人为产生的,比如下雨天的雨滴,渣土车的灰尘,严重的雾霾,林荫大道的树荫,突然飞入的大量的麻雀等等。
除非我们真的能打开深度神经网络黑盒,不然其中的安全隐患是永远无法消除的。
03、深度神经网络的「不可解释性」将给自动驾驶带来哪些难题?
由于神经网络本身不可解释,那么一些用于攻击或防御的算法也很有可能无法用数学去解释其原理,例如对抗样本的迁移性。
类似的例子还体现在神经网络的泛化、优化上。
在图像分类方面,深度神经网络效果确实比手工模型要好,以至于如今带火了整个 AI 领域,肯定是因为其在某个角度触碰到了真理,但我们既不知道是哪个角度,更不知道真理是什么。
不可解释性,导致人和机器之间没有办法协同。
任何两个主体之间要想协同,必须具备所谓的共同语言。如果机器的输出人不懂,人的输出机器不懂,导致人和机只能取其一,导致「1+1=1」,要么就全信机器,要么就全不信。
在很多风险敏感型的领域,医疗、军事、金融、工业,人不可能完全信赖一个机器的决策。
这种情况下,如果无法理解机器的输出,就会导致没有办法在这样的风险敏感型领域放心应用这样的技术和系统。
不可解释性,导致无法复现事故或错误。
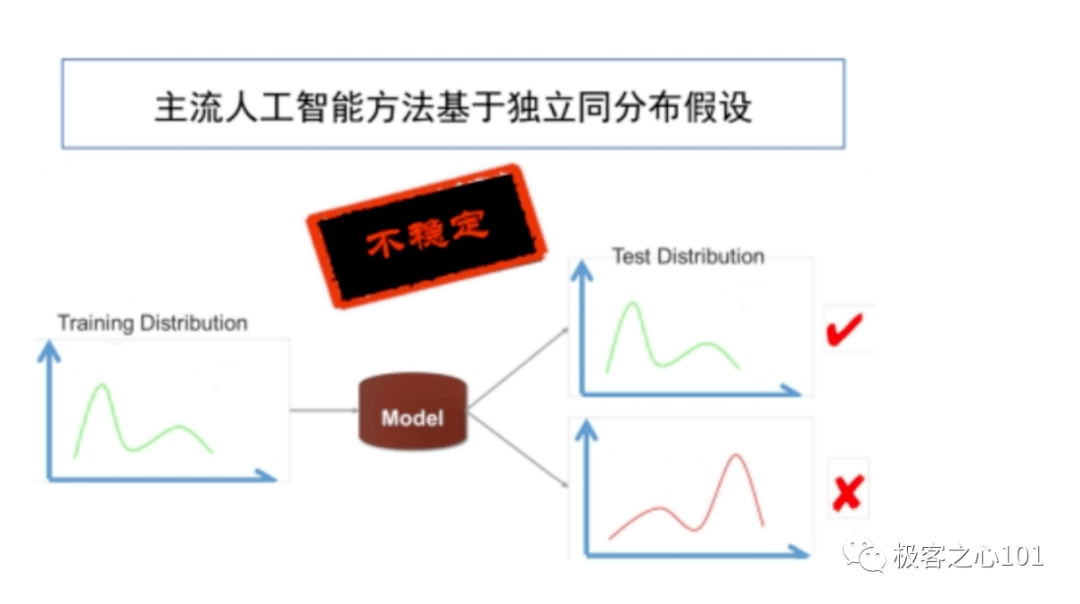
当前主流人工智能方法都有一个基本的统计学上的假设——「独立同分布」,即我们所训练的模型和所测试的模型要求是一个分布。
换句话说,就是要求测试模型的数据和训练模型的数据「长得像」,只有在长得像的情况下,我们现在这个模型的性能才是有保障的。
如果测试这个模型的数据分布和训练分布存在偏差,从理论和实际角度来讲,这个模型的性能不稳定且没有保障。
在实际的应用过程中,其实很难保证一个模型的测试分布和训练分布是一致的。
比如自动驾驶,我们在开发自动驾驶汽车视觉模块的时候会采集很多特征来训练这样的视觉模块,训练出来以后,再在特定的训练数据分布下训练该模块。
当实际产品上线后,没有办法保证司机会将该汽车驾驶到什么样的城市,以及这个城市的分布和训练数据分布是否大体一致——就像现在衡量算法都是去 KITTI 打榜,这样的成绩实际毫无意义。
说个有趣的例子,SpamAssassin 是一个垃圾邮件检测的开源项目,它在历史上出现过一个神奇的 bug,会把所有 2010 年之后的邮件全部判别为垃圾邮件。
因为在垃圾邮件这种强对抗场景里攻击方总在变换不同花样,它的 Bayesian 判别器按照年份调整了每个特征的权重,这本是一个合理的做法,但是训练集里没有 2010 年之后的数据,该判别器就本着宁可错杀也不放过的偏置将所有未知的邮件全部判断为垃圾邮件。
当然,SpamAssassin 的模型偏置提供了方便理解的证实预测的理由,这个问题很快就被找到并修复。
究其原因,由于是贝叶斯网络,是具备可解释性的,所以问题最终还是解决了,但深度神经网络可不具备可解释性,它可能在某一个领域持续犯错,但却无法修正,也就是说它无法迭代。
举例来说,无论特斯拉的 FSD 进化到哪个版本,它高度依赖深度神经网络,它可能跟最初版本没有任何提高,也就没必要进行 OTA 了。
不可解释性意味着其安全边界无法界定。
这不仅是说完全自动驾驶的 L5 不可能实现,局限在某个区域或某个限制条件下的自动驾驶 L4 也无法实现。
道理很简单,你不知道系统究竟在哪个范围内是安全的,这个限制区域或限制条件是无法界定的。
不可解释性,导致自动驾驶对算力无止境的追求。
地图四色定理的证明,数学家将平面图的构型分成 1936 种,然后用计算机逐一验证。当然在足够的算力下,这可以证明地图四色定理。
但是在这个过程中:没有新颖理论提出。换言之,机械蛮力代替了几何直觉。
神经网络深度学习也是如此,一切都是靠蛮力。
几千万甚至上亿参数,通过调整参数拟合输入与输出。目前所有的机器学习都是这样。
但人类不是如此,计算机图像识别里图像会被分成像素,而人类的视觉里没有像素概念,而是整体概念,比如一个苹果,计算机看到的是几百万像素,人类看到的是一个整体,人类只需要两三个样本甚至一个样本就能学会识别苹果,计算机需要几百万个样本,并且准确度不高。
神经网络只知道相关性,不知道因果性。
神经网络只知道这个测试与样本有强相关,可能是苹果,而无法解释为什么有关联,为什么是苹果。
因为无法解释,神级网络就不断增加深度和加大数据集。目前看来,貌似这两种做法能提高性能。
当然这只是猜测,毕竟深度神经网络不可解释。
这就带来另一个问题,那就是对算力的追求永无止境。
英伟达当然喜闻乐见,但对消费者来说就是成本不断增加。
业内把训练神经网络昵称为炼丹——类似于中世纪的炼金术和中国古代的炼丹,道士们不知道最后炼出来的是什么,反正就吃了。有时候确实有效果,也有皇帝因为吃多了仙丹而死,例如雄才大略的李世民。
那么,将来有没可能出现可解释的深度神经网络?
人类的基础数学理论已经停滞了近百年,没有重大突破。换句话说,人类智慧已经进入瓶颈期,想要具备可解释的深度神经网络完全不可能。
来源:第一电动网
作者:星河频率
本文地址:https://www.d1ev.com/kol/175564
文中图片源自互联网,如有侵权请联系admin#d1ev.com(#替换成@)删除。




先估价再买车,买的放心开的安心
您的询价信息
已经成功提交我们稍后会联系您进行报价!








 京公网安备
11010502033163号
京公网安备
11010502033163号