6月30日,普林斯顿大学发布了一项名为CEO-Bench的基准测试,旨在模拟创业公司环境,评估AI模型担任企业首席执行官(CEO)的能力。该测试通过模拟一个创业公司运行500天,考察AI模型在长期、多变量环境中的管理能力,涉及定价、预算、竞争分析和战略制定等复杂事务。测试中,AI智能体需要适应不确定性、在噪声环境中获取信息、适应外部世界的变化,并协调多个变量以服务统一目标。
在CEO-Bench测试中,智能体每周行动一次,可以无限轮调用34个工具,涵盖定价、增长、产品、运维等多个类别,并可查询19个业务SQL数据库。模拟环境包含26个客户群体,智能体需从订阅、流失、支持工单等反馈中间接推断客户的价格承受力和质量偏好。产品质量由日常开发、研究项目等多项投入共同决定。
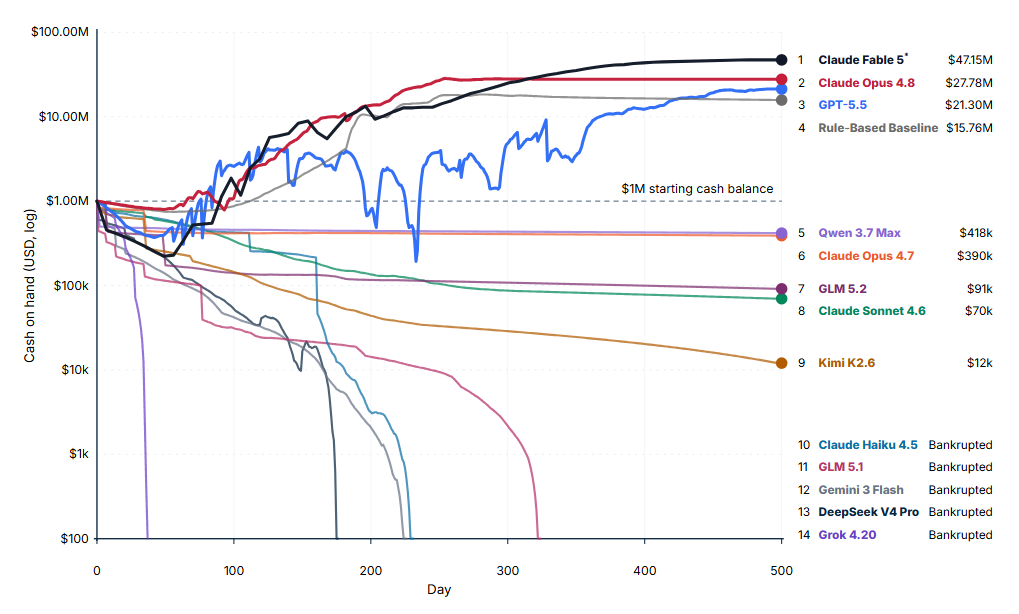
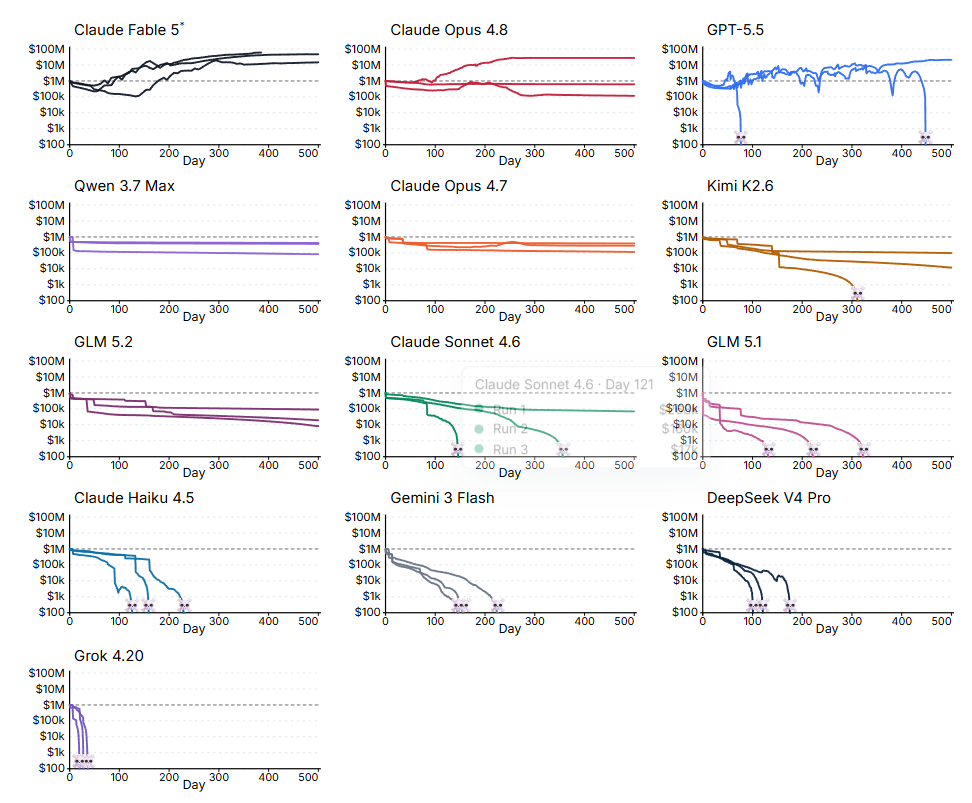
测试结果显示,多数AI模型难以在500天后保住初始的100万美元现金。在最佳单次运行中,ClaudeFable5的期末现金为4715万美元,表现最佳。而包括Grok4.20、DeepSeekV4Pro和Gemini3Flash在内的多款模型全部以破产告终,其中Grok4.20平均仅维持28天。ClaudeFable5是唯一一个多次运行结果均高于初始余额的模型,基于规则的基准模型最终余额为1580万美元。
来源:一电快讯
返回第一电动网首页 >
以上内容由AI创作,如有问题请联系admin#d1ev.com(#替换成@)沟通,AI创作内容并不代表第一电动网(www.d1ev.com)立场。
文中图片源自互联网或AI创作,如有侵权请联系邮件删除。







 京公网安备
11010502033163号
京公网安备
11010502033163号