今年,除了固态电池,自动驾驶领域的“端到端”,也在被狂炒。

特斯拉的示范效应真的很厉害,随着Tesla V12在北美大范围推送以及表现,“端到端”也成为了自动驾驶行业里大家最为关注的技术方向。
当然,国内最大的毛病众所周知,就是营销前置。就像固态电池,还没整出什么大规模量产,先在传播上来吹一波。而且,到了似乎不提端到端都不好意思出门的程度。
那么,什么才是端到端?这些真真假假的端到端,到底有多少干货呢?
端到端的“黑盒子”
先来理解一下,所谓“端到端”自动驾驶,打个不恰当的比方,就像做菜,你在“黑盒子”的这边输入食材,然后另一边一步到位输出做好的菜。
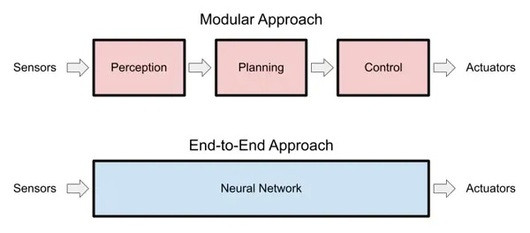
因为,现在主流的自动驾驶方案,都是模块化的。就是我们熟知的“感知、决策和执行”三大模块。而“端到端”就是把三个直接变成一个,从传感器数据输入开始,中间只要一步,到控制信号输出(马斯克所说的Photon to Control),实现完整闭环。
这个操作也树立了目前自动驾驶领域的最高水平和标杆,所谓“无招胜有招”、“一招制敌”。但是,这也反映了一个尴尬的行业事实,就是特斯拉在自动驾驶领域还是一骑绝尘的。
而这个来源于特斯拉CEO埃隆·马斯克(Elon Musk)口中的端到端,也就是End-to-End Deep Learning(端到端深度学习),简言之,就是要建立一个完整的学习系统,直接从原始数据中不断学习,并生成所需的输出,不需要人为将任务分解成多个中间步骤。
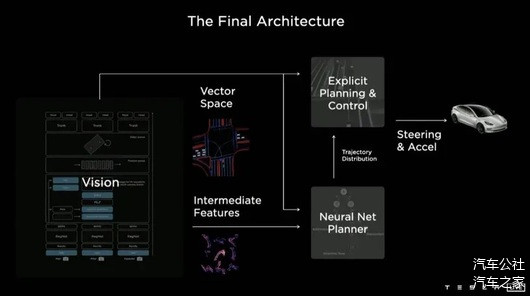
而当下普遍应用的三大模块的优点是技术较为成熟,开发起来的确定性更强。但是,这种技术架构下,自动驾驶车辆在极端案例(Corner Case)方面,仍然依赖工程师编写大量代码去制定行驶规则。
单靠数据训练出来的各个模块,很难处理没碰到过的情况,也就是需要不断用“规则”去填俗称为“坑”的各种Corner Case。同时,为了迅速扩大量产车上自动驾驶系统覆盖范围,车企不得不招募更多的软件工程师,比如,华为自动驾驶的规控团队就招募了上千名工程师。
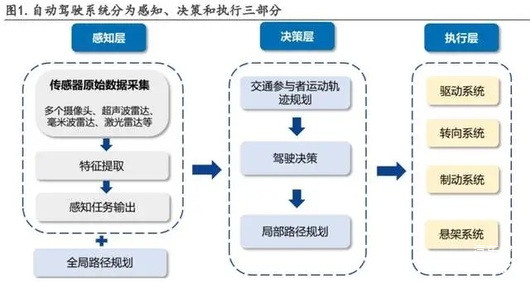
而自动驾驶方案中的模块化,也是不断进化而来。从2017年前的9个模快(仅感知环节就有检测、目标跟踪和融合数据3个模块),到多传感器融合后,现在的感知、决策(或者叫预测)和执行(或者叫规划控制)三大模块。
从“融合”的角度来说,当三大模块融合为一个“黑盒子”来输出执行结果的时候,实际上要求是更高的,不然特斯拉为什么这么多年才能推出端到端?对吧。背后是基于强大的DOJO超算中心,以及更多的GPU。
而且,这种彻底的端到端“黑盒子”,技术上很难进行Debug(调试)和迭代优化,同时由于传感器输入信号如图像、点云等是高纬度的,控制信号输出如方向盘转角和油门刹车踏板信号等是相对低维的,在端到端训练中非常容易“过拟合”,导致实车测试完全无法使用。
“没有金刚钻,不揽瓷器活。”国内最近一些企业则声称自己是端到端感知,或者端到端决策,只是各种细枝末节的“端到端”,这只能算作是纯数据驱动的感知和纯数据驱动的决策规划阶段。
换句话说,做得好点的还只是前两个模块的融合,根本做不到输出控制(执行)的结果。现在大肆宣传,不过是蹭热点、炒个概念。
端到端为什么会热起来?还有个因素,是去年商汤绝影的UniAD(Unified Autonomous Driving)获得了CVPR 2023 Best Paper最佳论文奖。虽说不算是众望所归,但也给自动驾驶行业注入了一剂强心剂。
但国内对UniAD褒贬不一,这种褒贬不一不仅仅体现在感知、预测、规控各个团队的独立视角上,还体现在自动驾驶领域学术界和企业界的鸿沟(Gap)。毕竟,企业面对的Corner Case也远多于学术界。
再说,故事讲得再流畅,毕竟需要量产落地。因为,预研的技术是要落到实车上才能最终体现价值。
但UniAD的论文里面没有提供实车数据(不包含Nuscenes)的数据和Demo,只有开环评测,没有闭环评测。
虽然北京车展上商汤绝影面向量产的UniAD完成上车演示首秀,但实际效果肯定是需要验证的。
端到端的难点
端到端自动驾驶的前景,肯定是光明的。但是,道路肯定是曲折的。
比如,端到端方案中的一体化训练就需要海量数据,因此,难点之一就在于数据的收集和处理。获得海量的行车数据,也是训练端到端自动驾驶模型的入场券。
马斯克去年在财报会上谈到过数据对自动驾驶模型的重要性,“训练了100万个视频Case,勉强够用;200万个,稍好一些;300万个,就会感到Wow;到1000万个,就变得难以置信了。”

而数据的收集需要大量的时间和渠道,数据类型除了驾驶数据外还包括各种不同的道路、天气和交通情况等场景数据,特别是,实际驾驶中周围方位的信息收集难以保证。
其次,数据处理时还需要设计数据提取维度、从海量的视频片段中提取有效特征、统计数据分布等,以支持大规模的数据训练。这点需要巨额的投入和成本。
因为,并不是所有的行车数据都可以用来训练端到端模型。有自动驾驶工程师就发现,原本积累的路测数据只有2%可用。想让端到端模型具备通用能力,必须用不同场景中的高质量数据训练模型。
还有,《马斯克传》中马斯克也亲口解释过,特斯拉全球200万台车每天约可收集1600亿帧的驾驶视频用于模型训练。但是,管理如此庞大的数据并非易事,因为绝大多数视频都是无用的。

真正宝贵的是那些车流量异常大、或是有众多行人做出各式各样的行为、路况极其复杂的画面,但是这个占比甚至连1% 都不到。而为了提取这1%画面,需要庞大人力、算力、储存甚至是电力等巨额成本。
就拿最重要的算力来说,门槛也极高。马斯克曾在今年三月初在X.com上表示目前FSD的最大限制因素是算力,而在得到缓解后,4月初马斯克又表示,今年Tesla在算力方面的总投入将超过100亿美元。
此外,2024年Q1财报会议上,Tesla透露如今已经拥有35000块H100的计算资源,而2024年底这一数字将达到85000块。这意味着,要达到跟目前FSD V12同样的水平,大概率35000块H100和数十亿美金的基础设施资本开销是必要前提。再往下,门槛还在进一步拔高。
数据获取成本高昂,再加上数据隐私和安全问题,数据标注和清洗困难,以及法律和监管限制等等,都限制着数据的获取。那么,国内的车企,又有哪个能承担如此高昂的这些成本呢?

除了数据收集的挑战外,“数据对齐”也是自动驾驶技术中面临的一大难题。
自动驾驶领域,面临着海量未标注的异构行为大数据。这些数据来自于不同的传感器、设备和环境,具有不同的格式和特征。要能用于自动驾驶的训练和应用,就需要进行准确的数据对齐。
而数据对齐的难点在于如何确保不同来源的数据在语义上保持一致。因此,往往涉及到复杂的语义理解和转换过程。这不仅需要先进的算法和技术支持,还需要对这个领域有深入理解。
所以,拨开营销的迷雾,我们就知道,端到端的真相是什么。
“简约不简单”,端到端不是说哪个单项做好就行,而是需要系统所有模块都达到一个较高的性能水平,才能在端到端的决策规划控制输出中达成较好的效果,这种端到端系统数据门槛,是远高于感知、决策、执行单个模块的数据需求的。
国内的企业,还是需要踏踏实实把脚下的路走好才是。
来源:第一电动网
作者:汽车公社
本文地址:https://www.d1ev.com/news/qiye/231939
以上内容转载自汽车公社,目的在于传播更多信息,如有侵仅请联系admin#d1ev.com(#替换成@)删除,转载内容并不代表第一电动网(www.d1ev.com)立场。
文中图片源自互联网,如有侵权请联系admin#d1ev.com(#替换成@)删除。




先估价再买车,买的放心开的安心
您的询价信息
已经成功提交我们稍后会联系您进行报价!

 京公网安备
11010502033163号
京公网安备
11010502033163号