两年前,日经亚洲评论刊登过一则报道:研究人员在拆解Model3后发现,Autopilot Hardware 3.0不仅是自动驾驶系统与多媒体控制单元的核心,更是让特斯拉甩开其他竞争对手的关键武器。
一个高性能的硬件平台,是处理预期增长的海量数据的基石,是自动驾驶系统不断精进的技术依托。事实也证明,特斯拉近些年一直走在自动驾驶队伍前列。但显然,这只是一道开胃小菜。数据才是那个压轴选手。

自动驾驶系统在前期开发阶段,需要采集大量的道路环境数据,形成贯穿感知、决策、规划与控制多环节的算法。随着自动驾驶等级每进一步,场景的长尾性将大幅增加,数据量也会呈现指数级增长。
量产车在上市后亦是如此,仍需持续不断回传场景数据,对算法模型加以训练和验证,做进一步的优化迭代。因而数据被认为是车企发展自动驾驶技术的护城河。截止到去年6月,特斯拉已收集100万支36帧10秒时长的高度差异化场景视频数据,累计数据量约1.5PB,远超Waymo。
如何获取、存储以及利用更多海量数据,是过渡到更高级甚至是实现完全无人化L5级自动驾驶的关键,也是越来越多的车企将目光瞄向超算中心的根本原因。
真正的主菜 无数据不智能
对于搭建自动驾驶系统而言,数据采集主要有两种模式,一是靠采集车预先采集,二是靠量产车路测回灌。一些打算从事自动驾驶系统开发的公司往往面临两个难题,创建数据采集车队难,打造量产车回传队伍更难。
结合IDC联合英伟达发布的白皮书,在实车端采集数据,需要真实车辆搭载全套传感器设备在真实场景中持续行驶,这通常会产生较高的测试成本。
与此同时,依靠实车路测难以对长尾场景实现全面覆盖;某些场景还具有一定危险性,极有可能增加测试成本。另外,仅仅通过实车路测无疑会拉长研发周期,难以满足当下市场对产品创新周期的需求。而一旦数据成了缺失项目,便无从谈起自动驾驶。
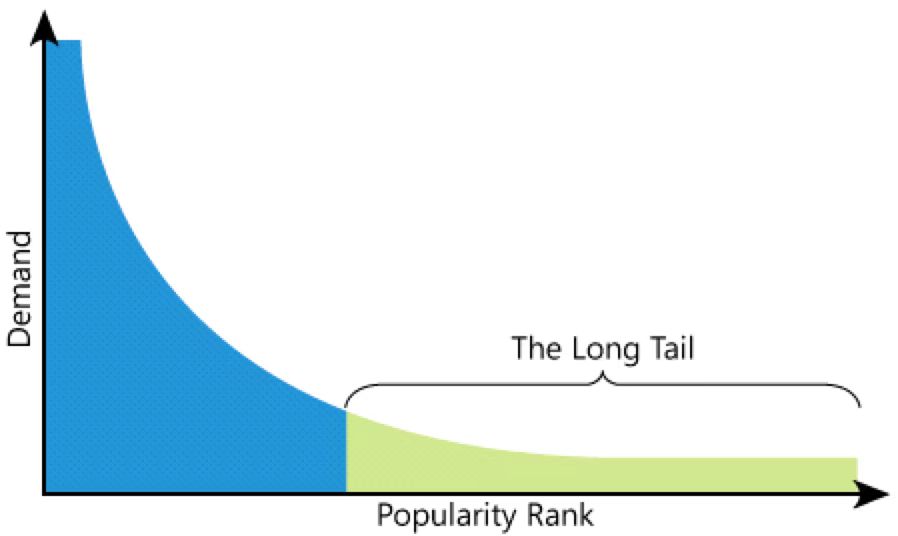
“长尾场景”即种类多且出现频率低的情景
自动驾驶时代,仿真由此成为硬需求。将真实世界中的物理场景通过数字建模进行数字化还原,自动驾驶系统便可以在虚拟环境中测试生成数据。
不仅测试速度优于真实物理世界的车辆水平,还可以在组装样车前就开启自动驾驶系统算法的测试。通过预先收敛的算法精度,也能进一步提升实车测试效率。毋庸置疑,一个高效精准的仿真工具尤为重要。
至于为什么需要智算中心,如果进行大规模仿真测试,一定时间里测试多个10亿量级的数据,算力将成为仿真效率的瓶颈。而算力早已不是一两张GPU或者一个小集群就能构建出开发的基础。
当数据变得越来越庞杂、越来越系统化,自动驾驶算法模型的复杂度不断提升,模型体积呈几何倍数增长,只有依靠数以百计、千计的GPU并行运算,才能在更长的训练时长中完成对Transformer等模型的训练,也只有数据中心能够支持这种需求。
“超算中心是算法的根本,如果没有超算中心,便没有办法打通自动驾驶这张牌。”英伟达汽车数据中心业务总监陈晔如此强调。这些要求都对数据中心的设计、建设和运维提出了更高要求。
造车新势力中,小鹏已经率先和阿里云携手在内蒙古乌兰察布发布了智算中心“扶摇”,算力可达600PFLOPS(每秒浮点运算60亿亿次),可将自动驾驶核心模型的训练速度提升近170倍。而蔚来、特斯拉等车企都选择了英伟达提供的解决方案。
其中,蔚来采用英伟达HGX加速器平台构建数据中心基础设施,在此基础上模型开发效率提高近20倍,加快了ET7、ET5等车型的量产上市速度。HGX整合了NVIDIA GPU、Mellanox等技术,以及在NGC(NVIDIA GPU Cloud)中优化的AI软件堆栈。

特斯拉也是利用英伟达GPU来构建自己的超算中心。在英伟达自动驾驶客户中,GPU使用规模最大的当属特斯拉,目前已经部署120个DGX SuperPOD 分布式集群。
“DGX”是英伟达最强的服务器,内置8张NVIDIA GPU,“SuperPOD”是英伟达推出的最小化可交付超算中心,内有20台DGX。换句话说,特斯拉整整用了2400台DGX,近2万张NVIDIA GPU。
“20台服务器能够做很多起步性的工作,但对于中国的造车新势力们来说,20台的数量远远不够。”据陈晔称,中国领先的自动驾驶客户的使用需求量在300到600多台DGX。
从完成数据采集、筛选到打标后,自动驾驶算法模型训练、回放性验证(推理过程)以及仿真测试这三大环节都离不开超算中心发挥作用。车企或者自动驾驶公司要想做好自动驾驶模型训练,一个大规模超算中心是必需品。这其实也是车企自建数据中心的底层逻辑。
建一座超算中心,就完了吗?
不过在起“量”之前,还有几个问题需要思考。
搭建超算中心不仅与服务器相关,还涉及系统构建,包括GPU集群、存储、高速网络、软件调度、机房管理、数据中心基础设施建设等内容。每个部分都涉及大量组件,增加了设计阶段的难度;
再者,无论是设备还是软件的部署,都需要一个较长周期,在统一协调部署和集成方面存在很多挑战;最后当数据中心设备全部安装部署完后,如何让其常用常新,一直保持最鲜状态,维持最好的工作状态同样至关重要。
市场研究公司Forrester早些时候在一份调查报告中指出,超过6成的受访企业认为自己的数据中心处于L3级阶段。
这项调查通过采访197位大中型企业的IT部门领导者和技术决策者发现,云计算、人工智能等技术有助于数据中心网络提升自动化和智能运维的水平,但由于相关企业在建设和运维阶段仍然依赖专家经验和员工技能,导致效率低且易出错。
在上述白皮书中还有一点,即无形的成本问题。车企和Tier1对搭建智算中心的预算普遍超过1亿元人民币,超过2亿元的占到五分之一。AI科技公司和自动驾驶独角兽也不乏投资过亿者,然而这些还只限于前期投入。
开发自动驾驶技术是个烧钱活,以Waymo、Cruise等公司为例,三五年烧掉几十亿美元是家常便饭。再尴尬一点,一些自动驾驶公司持续烧钱却毫无进展。硬件是钱,数据是钱,人才也是钱。

搭建人工智能计算中心投资金额(人民币);图片来源:IDC
比起自建超算中心,选择合适的供应商或许能够事半功倍。针对这些挑战,英伟达可以提供端到端,从芯片到数据中心的一体化解决方案。
以SuperPOD超级计算机来说,其拥有支持从小规模迅速扩展的参考架构,可以从20台变成40台、80台、1000多台,像搭积木一样不断拓展。同时具备持续的软件优化、“白盒”交付等特点。如此一来,车企便能将更多时间和精力聚焦在算法开发上,而非数据中心。
至少现阶段,超算中心比拼的不一定是规模和服务器的数量,诸如效率、开发方法也将决定着自动驾驶模型的进度条,而这里面不仅涉及硬件,还涉及开发的AI框架、方法、管理平台等等。谁能抢占先机,就有望先拿下一局。
英伟达会是唯一的答案吗?
从市场过往的发展规律来看,高科技行业的第一梯队将掌握在少数几家公司手中,随着科技新兵不断入场,绝对意义的寡头垄断格局只会越来越脆弱。
眼下数据中心处理器市场,英伟达、英特尔和AMD几乎100%形成垄断格局。单就GPU计算芯片而言,英伟达和AMD持续对垒,前者份额超过8成。目前自动驾驶算法模型的训练多以GPU为主,英伟达凭借以GPU构建服务器,基于“服务器+网络”构建超算中心的方案正在积极抢市。
围绕超算中心的战争已然打响,车企和自动驾驶公司要想拔得头筹,唯有快、更快地行动。
来源:盖世汽车
作者:徐珊珊
本文地址:https://www.d1ev.com/news/qiye/192464
以上内容转载自盖世汽车,目的在于传播更多信息,如有侵仅请联系admin#d1ev.com(#替换成@)删除,转载内容并不代表第一电动网(www.d1ev.com)立场。
文中图片源自互联网,如有侵权请联系admin#d1ev.com(#替换成@)删除。




先估价再买车,买的放心开的安心
您的询价信息
已经成功提交我们稍后会联系您进行报价!

 京公网安备
11010502033163号
京公网安备
11010502033163号