
对于自动驾驶的视觉系统而言,“看”到路人是一个基础工作,更重要的是,能否能像人类一样,判断出路人下一个动作将是什么。来自密歇根大学的团队,便研究了一种改进算法,让自动驾驶视觉系统能够对路人的行为进行预测。
视觉系统,不仅是用来看的,还能预测“未来”!
密歇根大学(University of Michigan)向来以自动驾驶汽车技术闻名,最近,他们又有了大动作——研究一种改进的算法,来预测路上行人的动作。

这种算法不仅考虑了行人在做什么,还考虑了他们是如何做的。这种肢体语言对于预测一个人接下来要做什么是至关重要的。

密歇根大学团队将研究成果发布在了Arxiv及IEEE中,有兴趣的读者可以访问上方或者文末链接进行详读。
本文提出了一种基于生物力学的递归神经网络(Bio-LSTM),该网络可以在全局坐标系下预测行人的位置和三维关节体位姿,该网络能够同时预测多个行人的姿态和全局位置,以及距离摄像机45米以内的行人(城市交叉口规模)。
“看”到更细节的动作,预测路人行动
关注路上行人并预测他们将要做什么是任何自动驾驶视觉系统的重要组成部分。

让自动驾驶车辆理解路上行人的存在,并分析一些细节信息,会对车辆一下步如何操作产生巨大的影响。
有些公司宣称其自动驾驶车辆的视觉系统,在这样或那样的范围/条件下可以看到并标记“人”,但目前很少人提出,可以看到并标记像“手势”或“姿势”这样更为细节的部分。
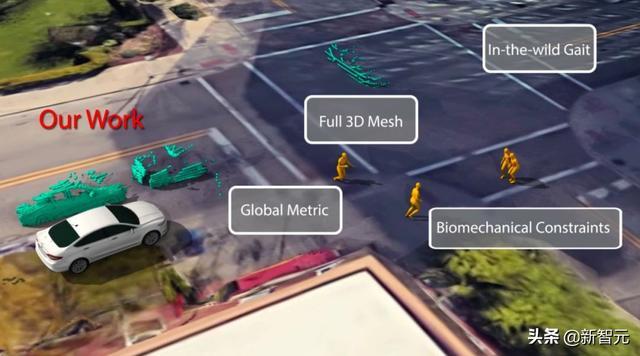
这种视觉算法可以(尽管现在不太可能)像识别一个人并观察他在几帧内移动了多少像素那样简单,然后从那个节点进行推断。但人类的运动自然要比这复杂得多。
UM的新系统使用激光雷达和立体摄像机系统,不仅可以估计一个人的轨迹,还可以估计他们的姿势和步态:
姿势可以表明一个人是否在靠近或远离汽车、是否在使用拐杖、是否在弯腰接电话等等;
步态不仅表示速度,也表示意图。
例如,路人将头转向他们肩膀方向时,他们可能接下来会转身,或者只是看了一眼肩膀然后继续向前走;路人伸出手臂,他们可能在向某人(或车辆)发出停车信号。
这些额外的数据将有助于视觉系统对动作的预测,使得导航规划和防止意外事件更加完备。




更重要的是,它只需要几个框架就可以很好地完成工作——可能只需要包括单步和手臂的摆动。
这就足以做出一个轻松击败简单模型的预测,这是一种关键的性能衡量指标。
来源:新智元
本文地址:https://www.d1ev.com/news/jishu/87147
以上内容转载自新智元,目的在于传播更多信息,如有侵仅请联系admin#d1ev.com(#替换成@)删除,转载内容并不代表第一电动网(www.d1ev.com)立场。
文中图片源自互联网,如有侵权请联系admin#d1ev.com(#替换成@)删除。




先估价再买车,买的放心开的安心
您的询价信息
已经成功提交我们稍后会联系您进行报价!

 京公网安备
11010502033163号
京公网安备
11010502033163号