英特尔火了!英特尔真的火了!
北京时间12月12日对英特尔来说大事连连,在北京,正举办20岁生日的英特尔中国研究院的隔壁楼房着了大火,而远在大洋彼岸,英特尔在加州Los Altos举办的“架构日”上连发大招!

英特尔高管、架构师和院士们展示了下一代技术,并介绍了英特尔在驱动不断扩展的数据密集型工作负载方面的战略进展,从而为PC和其他智能消费设备、高速网络、人工智能(AI)、云数据中心和自动驾驶汽车提供支持。

英特尔不仅展示了一系列处于研发中的基于10纳米的系统,将用于PC、数据中心和网络设备,并预览了其他针对更广泛工作负载的技术,还一连分享了聚焦于六个工程领域的技术战略,包括:
1、先进的制造工艺和封装。
2、可加速人工智能(AI)和图形等专门任务的新架构。
3、超高速内存。
4、超微互连。
5、嵌入式安全功能。
6、为开发者统一和简化基于英特尔计算路线图进行编程的通用软件。

英特尔表示,对这些领域的重大投资和技术创新,将为更加多元化的计算时代奠定了基石,到2022年,潜在市场规模将超过3000亿美元。

本次架构日的举办地加州Los Altos是仙童半导体与英特尔的联合创始人Robert Noyce的故居,该活动由英特尔公司处理器核心与视觉计算高级副总裁Raja Koduri与英特尔公司高级副总裁兼硅工程事业部总经理Jim Keller担任主讲。
Jim Keller一出场就怼了所谓摩尔定律大限将至的说法,他表示,在他看完整个英特尔的技术布局之后,深觉得他能够发挥的空间极大,他会让摩尔定律在未来很长的一段时间内持续下去,要大跌那些评论家的眼镜。

▲英特尔公司高级副总裁兼硅工程事业部总经理JimKeller
Raja则认为如今数据产生速度已远远超过出现有基础设施所能处理的速度,因此未来亟需更高效、规模更大且更具可扩展性的计算架构。根据现场媒体的报道,Raja预言说,未来10年计算架构的发展将远超过过去50年的速度。
Raja提到,由于计算产业的转变,未来英特尔在架构设计上也会越来越灵活,不但核心本身的设计会更接地气,同时也将更强调不同场景的计算适配,未来将引入CPU、GPU以外更多的计算概念,构成xPU生态。
基于不同时代所需要的计算架构不同,Raja将整个计算轨迹分为三个阶段,分别是2000年左右的GHz时钟速度阶段、2005年开始的多核阶段,以及未来的架构阶段,未来架构将是主导整个计算市场的最主要核心。Raja表示,英特尔将针对三大计算领域布局更广的计算架构,包括CPU和GPU在内的这些架构都将混合更多元、更具弹性的计算能力。

▲英特尔公司处理器核心与视觉计算高级副总裁Raja Koduri
针对AI应用这一当下和未来的主流计算趋势,英特尔也会在其主力架构中增加更多包含深度学习、训练以及推理计算加速的功能区块。
其下一代 14nm 处理器Cooper Lake将引进 AI 模型训练加速能力,支持 bfloat16的数据格式,可达到比 fp32高两倍的数据输出能力。
Raja还大秀英特尔在CPU以及GPU方面的最新布局,并展示未来英特尔CPU的核心发展路线,剖析了整个计算市场的走向。他也介绍了其最新的 Gen 11 世代绘图核心,并表示会将规模持续做大,设计出更符合全方位计算与绘图应用的独立GPU架构,正面迎击AMD与英伟达。

此外,存储、封装以及服务器的技术布局均在Raja本次全面介绍的射程之中。
作为xPU系列中的重要角色,Raja也不负众望的揭晓了众人关注的FPGA最新布局。Raja介绍道,新款的异构FPGA计算方案将会采用10nm制程,且规模将覆盖到从过去的中低端方案到高端方案,以同一架构不同规模的设计来解决不同层次的计算问题。而且下一代FPGA芯片会引入3D封装技术。


值得一提的是,在封装领域,英特尔推出的 Foveros 是业界首个真正的 3D 封装,可以把整个系统封进一颗芯片中,达成真正的 System in Package 概念,远比目前台积电与三星都在发展的 2D 或 2.5D 封装技术更为先进。
英特尔展示了Foveros全新3D封装技术,该技术首次引入了3D堆叠的优势,可实现在逻辑芯片上堆叠逻辑芯片,比目前台积电与三星在发展的 2D 或 2.5D 封装技术要更先进。英特尔预计将从2019年下半年开始推出一系列使用Foveros的产品。
首款Foveros产品将整合高性能10nm计算堆叠“芯片组合”和低功耗22FFL基础晶片。 英特尔称,它将在小巧的产品形态中实现世界一流的性能与功耗效率。
据称此封装技术可做到约1mm的超薄厚度,Raja还在现场秀出仅有12mm x 12mm尺寸的量产芯片。

Foveros为整合高性能、高密度和低功耗硅工艺技术的器件和系统铺平了道路,有望第一次将晶片的堆叠从传统的无源中间互连层和堆叠存储芯片扩展到高性能逻辑芯片,如CPU、图形和AI处理器。
因为设计人员可在新的产品形态中“混搭”不同的技术专利模块与各种存储芯片和I/O配置,该技术提供了极大的灵活性,并使得产品能分解成更小的“芯片组合”,其中I/O、SRAM和电源传输电路可以集成在基础晶片中,而高性能逻辑“芯片组合”则堆叠在顶部。
英特尔表示, Foveros将成为继2018年英特尔推出突破性的嵌入式多芯片互连桥接(EMIB)2D封装技术之后的下一个技术飞跃。
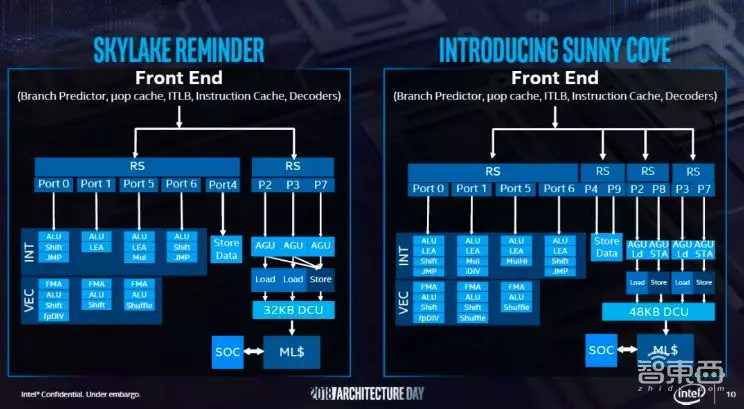
英特尔推出了接手 Skylake 的新一代CPU微架构Sunny Cove,旨在提高通用计算任务下每时钟计算性能和降低功耗,并包含了可加速人工智能和加密等专用计算任务的新功能。
Sunny Cove将在明年晚些时候成为英特尔下一代服务器(至强)和客户端(酷睿)处理器的基础架构。
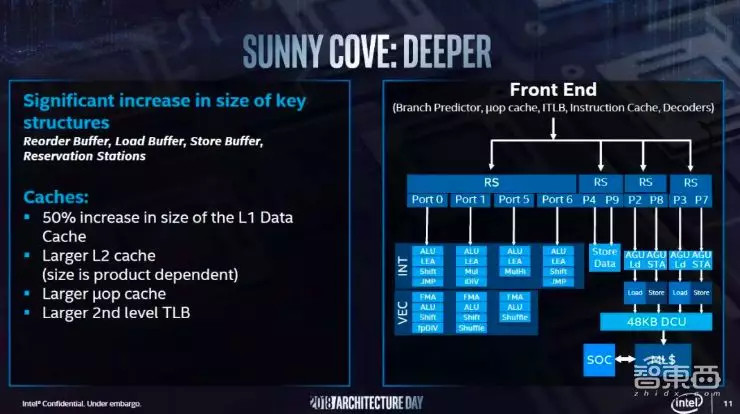
Sunny Cove的主要功能特性包括:
(1)增强的微架构,可并行执行更多操作。
(2)可降低延迟的新算法。
(3)增加关键缓冲区和缓存的大小,其一级缓存增大了50%,内存定址最大可定达4096TB,可优化以数据为中心的工作负载。
(4)针对特定用例和算法的架构扩展。例如,提升加密性能的新指令,如矢量AES和SHA-NI,以及压缩/解压缩等其它关键用例。

Sunny Cove不仅能够减少延迟、提高吞吐量,而且提供更高的并行计算能力。英特尔表示,它将有望改善从游戏到多媒体到以数据为中心的应用体验。
紧随Sunny Cove之后,Willow Cove和Golden Cove也将分别对缓存、晶体管进行更多优化,甚至会瞄准网络设备和5G应用等来进一步强化 AI 等关键应用的性能表现。
英特尔推出全新的第11代集成图形卡,配备64个增强型执行单元,比此前的英特尔第9代图形卡(24个EU)多出一倍,旨在打破每秒1万亿浮点运算次数(1 TFLOPS)的壁垒。新的集成图形卡将从2019年开始与10纳米处理器一起交付。此外,英特尔还重申了在2020年推出独立图形处理器的计划。
英特尔此前要在去年发布第10代集成图形卡,但由于改善幅度过小,最终该方案被舍弃,转而发展 11 代图形卡。

与英特尔第9代图形卡相比,新的集成图形卡架构有望将每时钟计算性能提高一倍。凭借高于每秒1万亿浮点运算次数的性能,该架构旨在提高游戏的可玩性。
此外,英特尔在此次活动上展示的第11代图形卡几乎将一款流行的照片识别应用程序的性能提高了一倍。
第11代图形卡预计还将采用业界领先的媒体编码器和解码器,在有限的功耗配额下支持4K视频流和8K内容创作。第11代图形卡还将采用英特尔自适应同步技术,为游戏提供流畅的帧速率。
英特尔还推出了新的One API项目,可以在单一开发环境之下,简化跨CPU、GPU、FPGA、人工智能和其它加速器的各种计算引擎的编程。
该项目包括一个全面、统一的开发工具组合,以将软件匹配到能最大程度加速软件代码的硬件上。其公开发行版本预计将于2019年发布。

英特尔还公布了英特尔傲腾技术以及相关产品的最新情况。作为一款新产品,英特尔傲腾数据中心级持久内存集成了内存般的性能、数据的持久性和存储的大容量。
这项技术通过将更多数据放到更接近CPU的位置,能够提高使应用在AI和大型数据库中的更大量的数据集能够的处理速度。
其大容量和数据的持久性减少了对存储进行访问时的时延损失,从而提高工作负载的性能。英特尔傲腾数据中心级持久内存为CPU提供缓存行(64B)读取。
一般来说,当应用把读取操作定向到傲腾持久内存或请求的数据不在DRAM中缓存时,傲腾持久内存的平均空闲读取延迟大约为350纳秒。
如果实现规模化,傲腾数据中心级固态盘的平均空闲读取延迟约为10,000纳秒(10微秒),这将是显著的改进2。
在一些情况下,当请求的数据在DRAM中时,不管是通过CPU的内存控制器进行缓存还是由应用所引导,内存子系统的响应速度预计与DRAM相同(小于100纳秒)。
英特尔还展示了基于英特尔1 TB QLC NAND裸片的固态盘如何把更多海量数据从硬盘迁移到固态硬盘,从而可以更快访问这些数据。
英特尔傲腾固态盘与QLC NAND固态盘相结合,将降低对最常用数据的访问延迟。总体来说,这些对平台和内存的改进重塑了内存和存储层次结构,从而为系统和应用提供了完善的选择组合。
英特尔宣布推出深度学习参考堆栈(Deep Learning Reference Stack),这是一个集成、高性能的开源堆栈,基于英特尔至强可扩展平台进行了优化。
该开源社区版本旨在确保人工智能开发者可以轻松访问英特尔平台的所有特性和功能。深度学习参考堆栈经过高度调优,专为云原生环境而构建。该版本可以降低集成多个软件组件所带来的复杂性,帮助开发人员快速进行原型开发,同时让用户有足够的灵活度打造定制化的解决方案。
(1)操作系统:Clear Linux 操作系统可根据个人开发需求进行定制,针对英特尔平台以及深度学习等特定用例进行了调优;
(2)编排:Kubernetes可基于对英特尔平台的感知,管理和编排面向多节点集群的容器化应用;
(3)容器:Docker容器和Kata容器利用英特尔虚拟化技术来帮助保护容器;
(4)函数库:英特尔深度神经网络数学核心函数库(MKL DNN)是英特尔高度优化、面向数学函数性能的数学库;
(5)运行时:Python针对英特尔架构进行了高度调优和优化,提供应用和服务执行运行时支持;
(6)框架:TensorFlow是一个领先的深度学习和机器学习框架;
(7)部署:KubeFlow是一个开源、行业驱动型部署工具,在英特尔架构上提供快速体验,易于安装和使用。

英特尔今年可以说是历经风雨,在市场上和AMD、英伟达等竞争对手交锋激烈,奉为圣经的摩尔定律又屡遭质疑。Jim Keller直接怼回去业界的风言风语、力挺摩尔定律将长存的行为,可以说是相当干脆和直率。
在2018年收尾之际,英特尔这一波大秀肌肉,可见其不但对未来产品架构走向有着清晰、全面且颇为自信的布局,而且做好了从多方面解决问题并满足一切计算需求的准备。
英特尔能否按着他们的既定计划顺利的走下去?10纳米PC芯片能否在明年如约而至?这些答案我们并不知道,但英特尔这次在战略规划上的全面布局,针对行业发展痛点各个击破的做法,一方面会成为芯片产业下一阶段发展很重要的参考,另一方面也让我们看到作为全球芯片巨头的英特尔发起威来,虎躯一抖也足够让芯片届为之一震。
来源:智东西
作者:心缘
本文地址:https://www.d1ev.com/news/jishu/83735
文中图片源自互联网,如有侵权请联系admin#d1ev.com(#替换成@)删除。




先估价再买车,买的放心开的安心
您的询价信息
已经成功提交我们稍后会联系您进行报价!

 京公网安备
11010502033163号
京公网安备
11010502033163号