新车发布会上,车企公布智驾行驶里程,已经成为了智驾秀肌肉的基本操作。譬如 8 月份,鸿蒙智行公布了智驾里程达到 2 亿公里。
车企之所以把智驾行驶里程拿到台面上讲,原因在于,这些真实的里程数据,构成了车企在智驾训练上的数字资产,帮助车企在模型训练上不断迭代升级。
这个过程发生在云端。
事实上,一个循环的数据流程在车端、云端之间 24 小时不间断运转。即车端将数据反馈给云端,在云端集中进行模型训练与仿真,再把模型数据发回车端形成闭环,完成 OTA 部署及更新。
所以车企总喜欢把「开得越多,越好开」放在嘴边,因为底层逻辑正是这样。这种「端到端」正是自动驾驶大模型固有的训练方式。
不过,这和现在行业热议的端到端自动驾驶并不同,它指代的则是一种技术路径,从输入端到输出端,从前被切分开的感知、预测、规划、控制等任务模块,贯穿成一个巨大的 AI 神经网络,它能像人类大脑一样快速作出决策。
有意思的是,这两种「端到端」正碰撞到了一起,还对模型训练提出了更高要求:
采集、存储百 PB 级别的数据量;
对高质量数据实现高效率处理、训练;
完成从感知到规控一体的仿真测试;
保证数据全流程的合规安全;
……
显然,这需要车企/智驾供应商投入巨大的时间成本与人力成本,构建出一套成熟、合规、稳定的数据工具链,以此支撑 AI 模型高效地迭代升级,模型的迭代效率越高,智驾产品落地速度越快,性能表现得越好。
对于车企/智驾供应商而言,从零搭建地基,挑战很大。
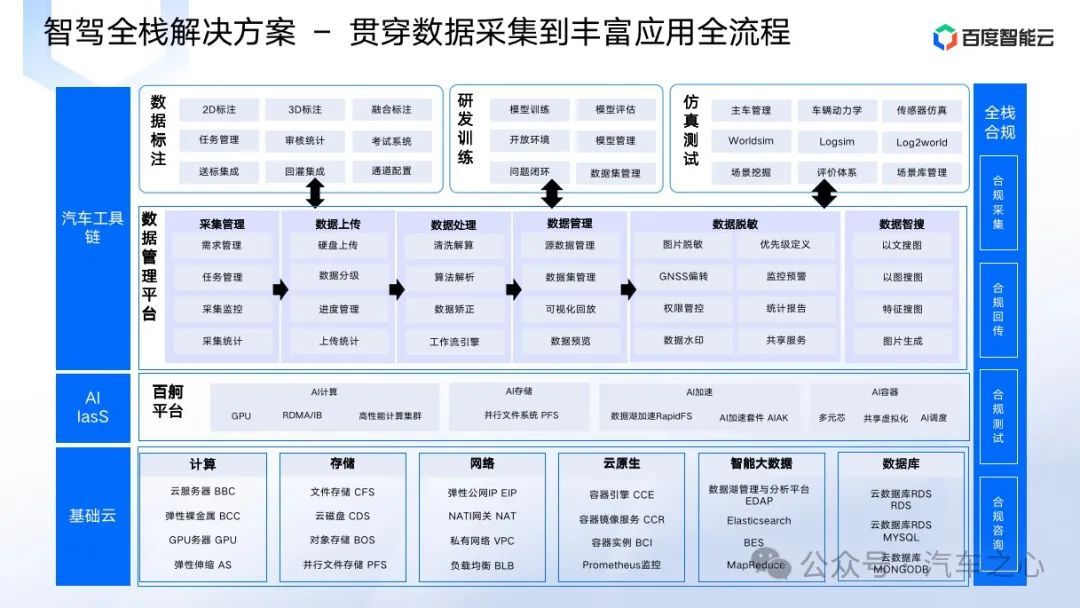
而以百度为代表的智能云服务商都看准了这种为车企赋能的巨大机遇,在汽车云建设上打造了一整套数据工具链,贯穿数据采集、标注、管理、仿真、测试等全流程,支持了业内大批企业自动驾驶服务的落地发展。
在最新一届百度云智大会上,百度汽车云迭代到 3.0 版本,围绕着端到端自动驾驶的特性对工具链做了针对性优化升级,助力自动驾驶玩家们打造高效运转的数据闭环,攻克端到端自动驾驶的落地难点。
01、用生成式 AI 解开「数据劫」
端到端技术范式,是行业公认通向高阶自动驾驶的最优解。
这种与 AI 深度绑定的技术路径,相当于把摩天大楼继续筑高,无疑给充当地基的数据工具链施加了更大压力。
一方面,数据规模开始疯狂扩大,数据处理难度上升。
一个大致标准是:
实现 L2、L3 级的自动驾驶 Demo 模型,只需要百万张图片的数据量;
实现 L2、L3 级自动驾驶的量产,需要亿张图片,数据量大于 100T;
实现 L4 级的自动驾驶 Demo 模型,存储数据量从 T 级进化为 P 级;
最后,实现 L4 级的自动驾驶量产,数据量已经大于 50PB。
很明显,每上升一个难度或层级后,数据处理变得越来越难掌控。
如果把自动驾驶数据处理链条摊开,可以看到这个流程包括筛选、清洗、标注等重点环节,这个步骤的关键目的是把真实数据变得有用。
端到端自动驾驶对于「数据有用」的定义,是系统通过数据训练实现强大的泛化能力,能够像老司机一样,应对各种复杂多变的驾驶场景,包括 Corner case(极端情况),如行人突然横穿马路、多路口环岛路线、极限直角型转弯等。
用一个比喻来讲,就是训练出一个聪明大脑,它不仅会做大量的常规题目,面对没有做过的难题时,也能冷静思考,合理分析,通过举一反三的方式写出正确解法。所以训练策略上需要注重广度和深度,用来训练的数据要足够丰富、多样、具备挑战性。
这就要求数据处理过程中,能从海量数据库中快速挖掘、标注这些高质量的题型,构成一个优质的训练集。
另一方面,仿真训练的逻辑发生变化,成为新的难题。
仿真训练相当于自动驾驶研发最后一道防线,验证评估。它好比一个专业的评价体系,给模型打分,分数高的才能进行到下面的车端部署环节上,分数低的则要找到 bug 点,回到训练模块重新优化。
目前,自动驾驶的测评分为两类,开环评估与闭环评估。
前者对于不同任务可以单拎出来,例如单独评估感知、预测、规划等环节的效果,与真实数据或标注数据相比对;
后者指在仿真引擎构建的虚拟世界中建立反馈闭环,从输入到输出端接受反馈信号,与现在行业反复提及的「世界模型」一个概念。
端到端自动驾驶由于感知、规划这些环节都连成一体,意味着它只能走闭环评估的路线,这就要求,底层的数据工具链也能支持这种一体化的训练方式。
另外一层难度,体现在仿真训练更需要庞大的数据支撑,因为它的本质是要建立一个虚拟世界,模拟车在真实世界中遭遇的一切,比如遇到水坑怎么过,前面迎面飘来塑料袋该做出什么反应,这需要包含许多长尾场景,并且场景要全面、真实,因为它是模型最后的评价体系,如果评价体系都不专业,那整个模型训练都是一场无用功。
所以,针对这些层面上的升级要求,百度汽车云对数据工具链产品做了不同程度的升级完善,主要体现在两点。
一是增加数据智搜功能,包括以文搜图,以图搜图。
这可以帮助数据管理平台快速完成数据筛选,精准找到高质量、有价值的数据,比如需要一个公路上路面积水的场景,可以直接用一张图、一句话描述,就能快速把相关数据锁定、检索出来,喂给 AI 模型做训练。
二是对采集数据进行生成式动作,用真实场景做仿真。
这可以实现对真实数据的再利用,正常情况下,一组高质量的数据只能作为一次场景使用,但通过生成式 AI,把场景中某个障碍物抹除,再注入新的车辆,就能生成其他同样真实的场景。
显然,这是一种降本增效的有利解法,尤其对于场景匮乏,路测数据不足的企业而言,生成式 AI 在有限成本基础上,让采集数据在更多的泛化参数下,得到有效利用。
英伟达全球副总裁、汽车事业部负责人吴新宙认为,随着端到端大模型上车,AI 将以无限度的规则重新定义汽车。
某种程度上,生成式 AI 与自动驾驶技术相结合,重塑智能化体验,指向了高阶自动驾驶的落地实现。
所以,要在汽车智能化下半场提高胜率,则是要学会四个字,借力打力,抓住 AI 这一变革力量,这是百度智能云正在做的事。
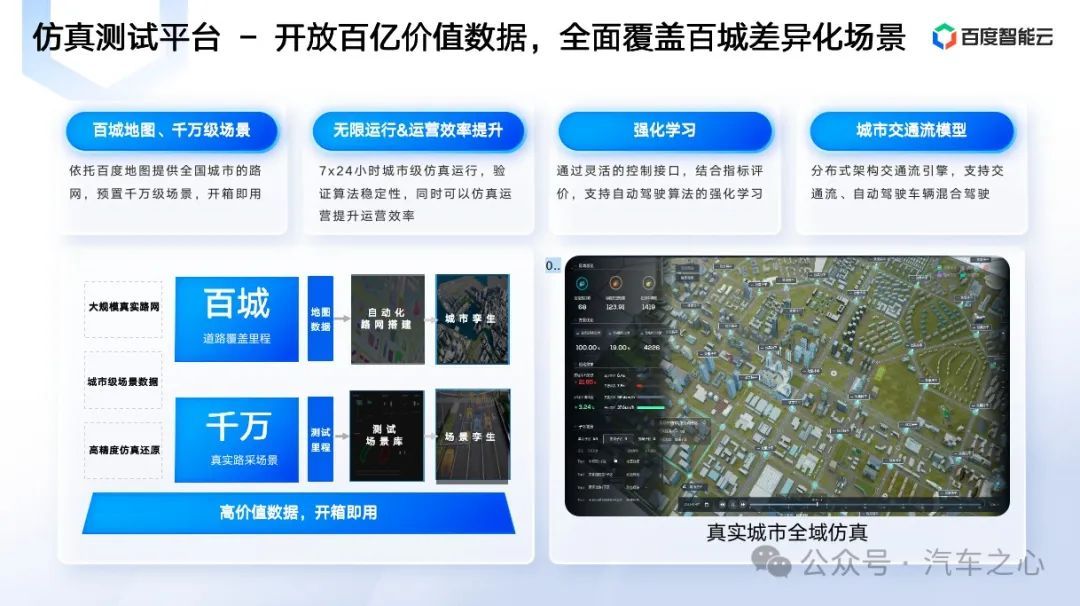
另外需要强调的是,百度本身作为自动驾驶的头号玩家,十年的研究历程下来,拥有真实、海量、丰富的数据资源,比如在百度地图支持下,拥有上百个国内主要城市全域数据,测试里程覆盖千万公里。这类丰富的数据资产对于建立仿真训练平台有极大的优势。
02、全链路训练优化,把算力吃透
某智驾供应商曾表示,数据会占据端到端自动驾驶开发中 80% 以上的研发成本。
这其中也包含了算力,庞大的数据资产需要强大的算力资源支撑。
尤其是仿真平台,大量仿真任务并发运行时,CPU、GPU 任务混合在一起,这对算力资源造车不小压力。
算力成为了自动驾驶玩家们锚定的军备竞赛,这指向了两种统一动作。
一是兴建智算中心。
以特斯拉为例,其消耗数十亿美金兴建超算中心,预计今年底算力最高将达到 100E FLOPS。
国内智驾玩家显然不具备这番资金实力,但在智算中心的算力投入上,一直不遗余力的提高上限。
二是打造世界模型。
端到端自动驾驶对于「验证」的高要求,使得世界模型/仿真平台成为智驾企业的加码重点。
尤其是生成式 AI 出现后,这种模拟现实的强大工具被深度应用在世界模型/仿真平台的搭建中。
与之伴随的,是对算力的高需求与高消耗。
据悉,端到端自动驾驶的起步算力,大概在 1000P 左右。越往上走,算力要求越高,成本负荷越重。
与此同时,还伴随着一个难题,即算力效率低,如果算力冗余,没有得到充分利用,那在算力上花费的资金成本则又被砌高了。
所以关键是把有限算力发挥出最大价值,降低成本和时间,提高迭代速度。
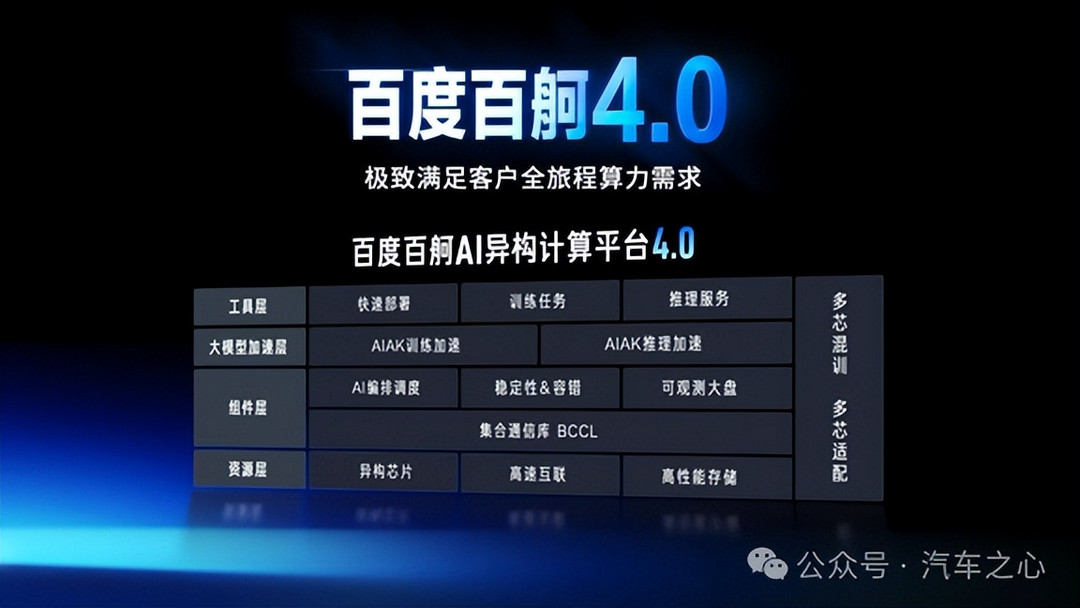
百度智能云的算力服务优势由此凸显出来,推出了百舸· AI 异构计算平台 4.0,提供了一套低成本、高效能的优化方案。
百度百舸 AI 异构计算平台 4.0
这里值得一提的是,百舸平台为了追求训练的极致性能,除了追求单卡本身的训练性能,也重视多卡之间的并行效率。
这种多芯训练,使得平台能够支持不同类型的芯片算力运转,包括 A100、A800、国产芯片等,还能够支持万卡规模的大型集群,进而帮助模型提升计算效率。
另外,百舸平台这种端到端加速能力,对于不同的算法框架也做到了泛化性适配。
一个热知识是,同一个算法模型在不同的训练框架上获得的优化能力不同,如果算法框架和模型的耦合能力差的话,还会造车算力资源使用差的负收益。
所以百舸平台基于自动调优策略,通过并行优化、显存优化,各种算子、存储、网络的各方面优化行为,最大程度提高了训练效能。
可以通过一组数据论证:
在标注场景下,百舸平台的 GPU 共享方案将自动化标注的成本降低了 1 倍以上;
在模型训练场景下,百舸平台帮助模型训练吞吐平均提升 138%,最高 400%,最多缩短 80% 的模型训练时间;
在仿真场景下,百舸平台可以支持仿真平台实现日行百万公里的仿真里程。
一个真实案例是,某头部车企通过百度智能云助力,模型训练性能提升了 170%,GPU 的资源效率提升了 2.5 倍。
显然,百舸平台作为强大的 AI 基础设施,让算力资源在多样化场景下得到充分发挥,帮助智驾企业们抓住研发效率这个核心竞争力。
03、云智一体,加速智能化终局
智能化的下半场,比拼的核心在于基础设施——汽车云的能力,这决定水面之上性能的上限。
在这种云智一体的生态中,同样能看到两种趋势正在生长。
一是车路云结合,把路测的数据引入进来。
以往在路上开车,遇到交通事故、施工路段往往需要承受长达几小时的堵塞折磨,这给出行带来极大的不便利性。
而百度智能云和路测交通集团合作,把数据联通后。这些动态的路况,以及天气信息,都能早早通过 AI 提醒获得,用户可以提前根据信息规划线路,保证出行的通畅。
比如,有车企就通过公交车的潮汐车道数据做路径规划,用户可以巧妙避开堵塞路段,提升驾乘体验感。
值得一提的是,这种路况提醒,可以建立在不开启导航地图的基础上,直接通过智能座舱实现。
这也指向了第二种趋势,即智能座舱的体验感越来越好。
在 AI 大模型上车后,智能座舱从多模态的交互性演变成 AI 的主动性越来越强。
也就是说,从用户主动发起问答式、指令式对话,AI 准确理解并回答、执行,变成 AI 主动揣测用户需求,在恰当的时机发起相关对话,推送对应功能等。
另外,智能座舱的体验感也在逐步提升,比如极越 01、07 等车型上车了百度的座舱大模型后,能做到车外语音控制,通勤自动导航等功能,并且还能通过「哨兵模式」,在车未启动时,帮助用户自动记录到车辆剐蹭等意外情况,并自动启动行车记录仪保留证据。
一个确定路径是,伴随着自动驾驶、智能座舱向更高纬度的性能进阶,云服务商都在抓住这种为车企赋能的机遇,不断推出具备竞争力的服务方案,在数据工具链的产力上内卷。
小马智行 CTO 楼天城在最新采 访中表示,数据链的成熟度,决定了最后模型好坏的关键。
而有能力把数据链做到支撑 L4 的一定是百度。事实上,百度本身就在 AI 领域长期积累,打造的 Apollo 平台具备支撑 L2 至 L4 的量产落地实力。
而百度作为头部自动驾驶科技企业,选择以一种开放的心态来做云服务,把核心工具链开放给行业使用。
根据全球领先的 IT 市场研究和咨询公司 IDC 发布《中国人工智能公有云服务市场份额,2023》报告显示,2023 年中国 AI 公有云服务市场整体规模达 126.1 亿元人民币,百度智能云市场份额以 26.4% 的成绩排名第一。
值得一提的是,自 IDC 发布中国 AI 公有云市场报告以来,百度智能云已经连续 5 年蝉联中国市场第一。
在汽车行业集体拥抱智能化的今天,没有一家车企能做到全栈自研,绝大多数都选择与云服务商来个双向奔赴,在强大的数字基建上构建智能化壁垒,也正是在这种合作共赢的生态下,智能驾驶的想象力能够进一步延伸,并一步步转变为现实。
来源:第一电动网
作者:汽车之心
本文地址:https://www.d1ev.com/kol/248455
文中图片源自互联网,如有侵权请联系admin#d1ev.com(#替换成@)删除。




先估价再买车,买的放心开的安心
您的询价信息
已经成功提交我们稍后会联系您进行报价!











 京公网安备
11010502033163号
京公网安备
11010502033163号