
5 月 21 日,雷军直播小米 SU7 NOA 时,他说了这样一句话:「目前业内实现智驾全自研的,国内有 7 家公司,都是决心强大」。
雷总口中的战国七雄是谁,舆论场有无数组合。但当我们把目光回到技术本身,一个关键词语,这两年成为证明车企自研智驾决心,甚至引发暗自较劲的热词:
训练算力,以及有关训练算力的资金投入。
这场算力大赛,在 4 月 28 日被马斯克直接拉到天花板。
他在 X 上说,「特斯拉今年大概会投资 100 亿美元,用于训练和推理结合的人工智能,后者主要用于汽车。任何没有这种规模投入的企业,并且高效推进,没法玩(cannot compete)」。
100 亿美元约合 723 亿元人民币,整个华为 2023 年研发投入是 1647 亿元,723 是 1647 的 43.9%。
这笔钱让马斯克拥有了全球最高的「计算卡」储备:到 2024 年底 85000 块英伟达 H100,直接成为全球最大的「卡皇」。
如果说自动驾驶可以引发下一次生产力爆炸,那么目前谁拥有的训练算力越多,谁就更接近于造出第一颗自动驾驶「核弹」。
于是我们不禁好奇:同样竞逐智能驾驶高峰的「蔚小理特华米」们,他们手握的智能驾驶「核弹当量」之间,有没有距离?如果有,差距在哪里?
今天数字轰炸。

E 时代
先聊聊时代背景——E 这个字母,大家这两年从车企那里听得不少。
算力语境里面,E 指的是 Exa,1Exa 翻译过来是 10 的 18 次方,一百亿亿。

比如 4 月 11 日的鸿蒙智行春季发布会上,余承东表示,目前华为的云端训练算力,已经达到了 3.3EFLOPS;相比去年 11 月智界 S7 首次发布时公布的 2.8EFLOPS,又提升了约 20%。
为什么进入 E 级训练算力时代,对于智能驾驶如此重要?
训练 training,在人工智能领域指的是学习,也就是用巨量数据「喂」出一个足够强大的神经网络模型;推理 inference,指的是基于这个训练好的神经网络模型,使用新的、规模相对很小的现实数据,得出预测结果。
常见的 Orin X,就是用于推理的小算力芯片;A100/H100,就是用于训练的大算力芯片。

或者举个很形象的例子,推理芯片是学生拿着现成的教材学习,学习芯片就像是教案组编教材,两者的难度有本质不同。
结果就是,掌握的智能驾驶训练算力越庞大,离那本「万能教材」就越近,起码在舆论层面,可以营造这样的氛围。

蔚小理华们的算力军备
了解完背景知识,我们需要解答一个问题:蔚小理华米们,手里有多少训练算力资源?
作为智能汽车新军,截止我们发稿,小米汽车目前尚未公布训练算力具体规模。
但看完本段,你会对小米汽车需要「卷」到的算力规模,有一个大概认知——想要维持「战国七雄」的地位,3 个 E 的算力是起步。
华为系的算力前面已经提到过,3.3EFLOPS 的规模堪称庞大。而且在 4 月 25 日的北京车展,华为乾崑发布会上,这个数字已经迭代到了 3.5EFLOPS(算力精度未知)。

那蔚小理们呢?
有意思的是,目前来看,蔚小理三家各自走了不同的算力扩张方向。
先说蔚来吧,去年 9 月份的 NIO IN 全栈技术发布会上,任少卿晒出了这样一张 PPT:38100POPS 的「群体智能车队算力」,约合 38E,看起来相当炸裂(INT8 精度)。

NIO Day 2020 上,蔚来发布了 NT2.0 平台,四颗英伟达 Orin X 的配置堪称奢华。直到那张PPT,大家才真正知道第四颗 Orin X 的用途(一颗安全冗余)。
不过,按照 NIO IN 的信息,每台 NT2.0 上的其中一颗 Orin X,承担的实际上是本地智驾路线的快速验证。
所以,它不是传统意义上的「人工智能大模型训练」,实际上的 NAD 中央智能计算集群,算力是 1400P,约合 1.4E(算力精度未公布)。

上面提到的 38E 群体算力,更像是广义上智驾训练的其中一环,也是蔚来随着保有量上升,加速智驾功能落地的独家武器。
然后聊聊理想,目前披露的信息不多,只有 2023 年的一些旧闻。
去年 6 月,理想汽车智能驾驶副总裁郎咸朋表示,目前理想拥有 1200PFLOPS 的训练算力(精度未知),约合 1.2EFLOPS。
不过,另一则消息,透露了更多细节。
同样是去年 6 月,雷锋网报道称,理想向字节跳动旗下数据服务公司火山引擎,租用了 300 多台英伟达人工智能训练服务器,用以训练智能驾驶大模型,这一批服务器的总算力超过 750PFLOPS。

如果报道属实,这意味着理想租用的,是英伟达上一代人工智能服务器 DGX A100,平均每个 DGX A100 的 FP16 精度算力为 2.5PFLOPS,换算成 FP8 就是 5PFLOPS,累计约 1500PFLOPS,约合 1.5E。
租用服务器的好处,在于资产负担相对小,尤其对于进展迅速的半导体行业——2024 GTC 大会上,英伟达已经拿出了 A100 的下一代的下一代,B200。
当然,长期采用租赁的形式,对供应商能力的依赖、数据/模型交流的延迟,都需要斟酌。
最后聊聊小鹏。
520 发布会上,何小鹏表示目前小鹏汽车今年会拥有超过 7000 张卡,每年会在算力上投入 7 个亿。
这两个数字是什么规模?

先来算算卡,H100 有很多个版本,但只有最贵也最强的 H100 SXM,可以组成延迟最低的 DGX H100 训练服务器,或者说这就是黄仁勋给车企/科技公司准备的豪华套餐。
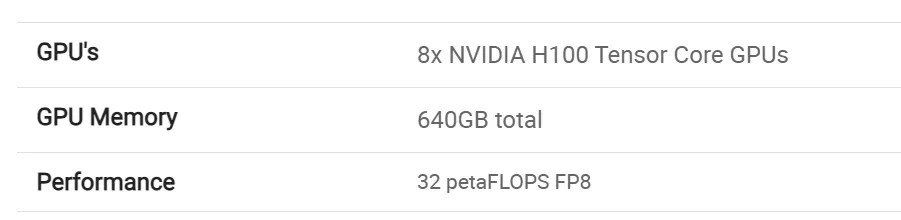
如果这 7000 张都是 H100,也就是 28000PFLOPS 的 FP8 算力,换算下来约合 32E,放在「云端训练算力」语境里面,竞争力当然极强的。
而如果这 7000 张都是 A100,那么估算结果大概是8.75EINT8,也够卷了。

然后算算何小鹏的 7 个亿。
补充一个背景知识,其实现在 DGX H100 国内都可以买到,大家作为个人都能买,只是需要经过代理,而不是直接一个电话打给老黄。闲鱼渠道显示,一台 DGX H100 的报价在 250 万元以上。

换算下来,7 亿元可以买到大概 250 台 DGX H100,里面是 2000 颗 H100 SXM,估算算力约为 8 个 E。
这也是我们惊讶于何小鹏直接「梭哈」的原因,预算+行情=实力,小鹏汽车这次是直接将牌甩在了桌上。
当然,高达 32 个 E 的估算规模,能佐证何小鹏的信心——在国内来看,足够梭哈了。

全球第一当量?
4 月 24 日,我在北京采 访了英伟达数据中心副总裁 Norm Marks。
Norm 分享了这样一张图:各家客户目前已拥有的「DGX equivalant nodes」。
这个词的意思,是手里的卡等效于多少个 DGX H100 节点,而非真的拥有这么多 H100——因为还算上了上一代的 A100。
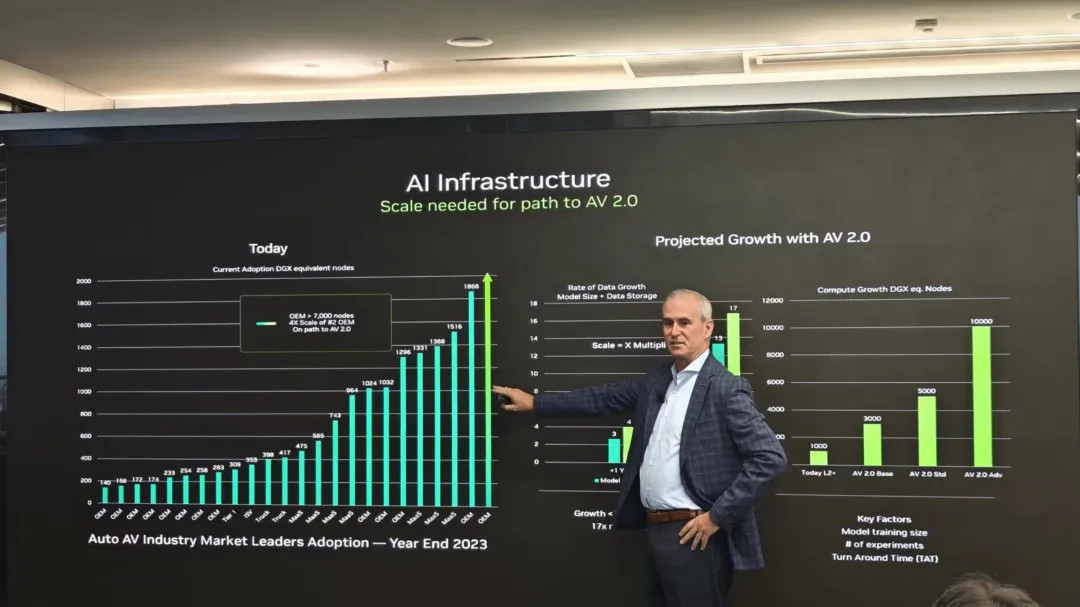
可以看到第二位是一家 OEM(主机厂),它有 1866 个等效 DGX H100 Pods,算力规模大概是等效不到 1.5 万块 H100 吧。然后重点来了,第一位也是一家 OEM,看起来没多多少?实际上是图表不够地方画柱状图了——第一位是第二位的四倍多!换算下来大概是超过 6 万块 H100 的算力。然后 Norm Marks 来了句:「You know who it is.(笑)」。背景知识是,他说这句话的五个小时前,马斯克说到 2024 年底,特斯拉会拥有超过 8.5 万块 H100 的算力规模。
85000 块 H100 有多少算力?
一块 H100 最高是 3958T,85000 块最高是 340EFLOPS(FP8),三位数的 Exa 级算力。
这样写可能还不够直观,一块 Orin X 是 254T(INT8),340E 大概就是 133.9 万块 Orin X,相当于 67 万台小米 SU7 Max,或者其他用了双 Orin X 的车型的算力总和。
当然马斯克给了个更广泛的语境「人工智能」,而不只是「自动驾驶」,但他还有另一句话:「自动驾驶就是真实世界里面的人工智能」。
马斯克手里的 85000 块 H100,组成了 2024 全球智能汽车领域的究极核弹,上面标橙的那句话,可能会成为这颗核弹的引爆按钮。
最后,我们可以总结下,按照目前披露的信息,这几家可以估算,或者已经公布的训练算力规模如下(华为蔚来未公布算力精度,理想未官方公布训练卡总数):
特斯拉 2024 年底约为 340E;
蔚来 1.5E 中央训练+38.1E 边缘群体算力;
小鹏年底约为 8.75-32E,7 亿元每年能买 8E 以上;
理想根据去年报道,约为最高 1.5E;
华为系 3.5E,但两个星期就增长了 0.2E;
小米汽车目前未公布。
算力看不见摸不着,但算力制霸背后需要极重的资源投入,从资金本身,再到数据运转的体系,甚至企业梭哈自研智驾的决心。
你买车的时候,会看「训练算力」吗?
(完)
来源:第一电动网
作者:电动星球News蟹老板
本文地址:https://www.d1ev.com/kol/232417
文中图片源自互联网,如有侵权请联系admin#d1ev.com(#替换成@)删除。




先估价再买车,买的放心开的安心
您的询价信息
已经成功提交我们稍后会联系您进行报价!








 京公网安备
11010502033163号
京公网安备
11010502033163号