在基于GPT-3.5的ChatGPT问世之前,OpenAI作为深度学习领域并不大为人所看好的技术分支玩家,已经在GPT这个赛道默默耕耘了七八年的时间。
好几年的时间里,GPT始终没有跨越从“不能用”到“能用”的奇点。转折点发生在2020年6月份发布的GPT-3,从这一版本开始,GPT可以做比较出色的文本生成工作了,初步具备了“智慧涌现”能力。
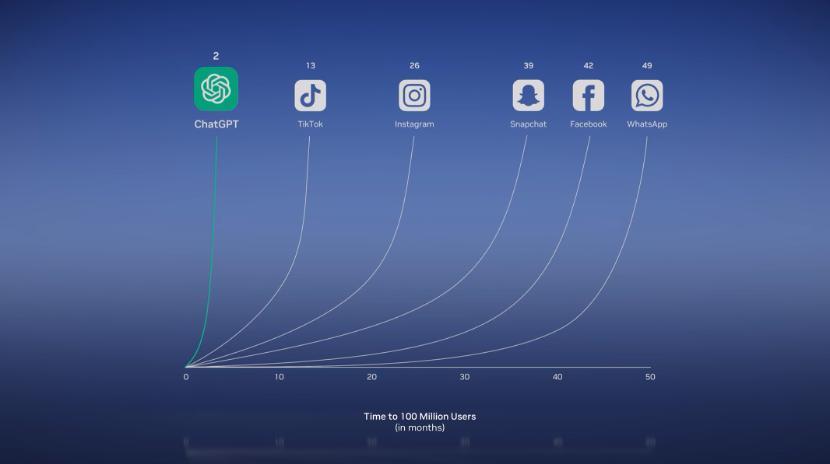
再后来,OpenAI在GPT-3.5里加入了个人机交互界面,做了聊天机器人ChatGPT,迅速席卷全球,在短短的两个月的时间里,用户数量迅速突破1亿大关。
图片来源:英伟达
海外的谷歌、Meta、特斯拉,国内的百度、华为、阿里、字节这些互联网巨头纷纷加码在GPT大模型上的投入,再后来,本土电动车企形形色色的GPT也陆续问世了。
自2023年第四季度开始,问界M9上的盘古大模型、理想OTA5.0里的Mind GPT,蔚来汽车上的NOMI GPT、小鹏XOS天玑系统里的XGPT陆续上车,不仅帮你写诗,还能帮你做事。
那么,这些车载GPT是如何横空出世的,它们又将为汽车上带来何种变化呢?
早期,没有在大模型方面布局的本土车企是借助国内外开源的基础大模型自研GPT,这应该也算是业内公开的秘密。原因无他,真正自研大模型实在太消耗资源了。
大模型的赛道非常卷。为了缩短训练时间,且提高训练效率,OpenAI、谷歌、Meta这些巨头的基础大模型都是投入大几千张甚至几万张A100、H100显卡训练出来的。
1万张A100大约对应3.12E的训练算力。公开信息显示,国内头部车企里,华为用在汽车业务上的训练算力3.5E,百度为2.2E,蔚小理的算力规模都在1E左右。
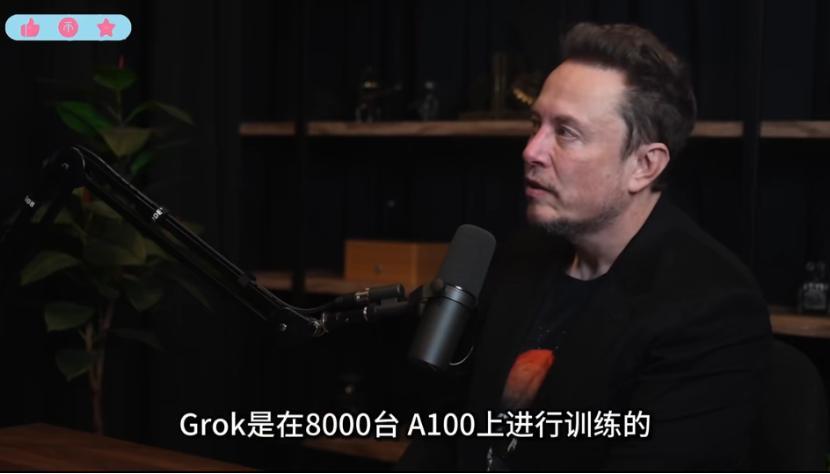
在一次访谈中,马斯克透露过xAI的Grok(据说要上特斯拉的车)训练投入了8000张A100。从GPU小时来算,且不说这些闭源的参数量奔着万亿级别而去的大模型,即便那些开源大模型,其消耗的GPU资源都是不可承担之重。
据悉,Meta开源的LLaMA-2-70B的大模型,使用了2000个英伟达A100训练,耗费了172万个GPU小时;地表最强开源大模型Falcon-180B,使用了4096个A100 GPU,耗费了约700万 GPU小时进行训练。
来源:马斯克访谈
无论从什么角度,不以大模型为主业的本土车企,都不可能为这个赛道投入这么巨大的资源,而且,几万张A100/H100(百亿美金)远不是这些现在基本上还无法盈利、只能依靠资本市场输血的车企所能承担的了的。
所以,采用开源大模型自研可满足车用场景的GPT,成了本土车企的捷径,也几乎是唯一可行的路径。
只有少数巨头强势赋能的车企,才会采用了自研基础大模型的方案。比如,华为系的问界、智界和百度系的极越,真要算起来,华为的盘古大模型和百度的文心一言问世的时间也不短了。
稍许遗憾的是,这两个大模型至今没有产生破圈效应,GPT上车的时间也并没有比蔚小理早很多。
这背后有一系列复杂的原因。
一方面,正如华为高管在2023年的华为开发者大会上所说的那样,“我们的大模型不做诗,只做事”,因为一直做着to B的生意,没有to C,所以没有被大众所熟知。
另一方面,盘古大模型和文心一言之前基础能力不足,基础能力的不足来自于参数规模比较小、训练数据和训练时间不足。
必须承认,直到OpenAI的ChatGPT问世之后,整个行业及业界专家才真正接受了比例定律Scaling Law,建立了可以通过扩大模型规模、增加训练数据量、延长训练时间实现模型性能持续提升的“信仰”。
信仰不足、意见不一是之前不够大的大模型基础能力不足,从而没有产生破圈效应的重要原因。
即便认可了比例定律的第一性原理,要从千亿参数迈进到万亿参数,也需要对模型设计做大量的科研工作,才能解决参数数量级提升引发的梯度爆炸等一系列问题。
无论如何,虽然同是率先将大模型技术搬上汽车的第一阵营,华为(问界和智界)/百度(极越)的大模型上车路径和蔚小理还是有着明显的区别,其本质的区别就在于前两家的基础大模型来自自力更生,而新势力的基础大模型很大可能来自于业界的开源方案。
除了参数量达到1800亿的Falcon-180B(去年9月份开源),开源基础大模型的参数一般都在几百亿级别。这是巨头的游戏。
扎克伯格的Meta是开源大模型的主要贡献者,它们开源的LLaMA-70B的参数在700亿左右。
另一玩家是谷歌,也许是意识到了无法打败OpenAI,带着搅局或者不想让OpenAI垄断基础大模型市场的心思,谷歌正加快开源的动作,它最近开源了两个大模型——Gemma 2B和7B,可分别在端侧和云端部署。
根据这些巨头宣布开源大模型的时间做一个推论,蔚小理等本土车企们用的开源大模型的参数量大概在千亿左右。
这些开源基础大模型提供的不只是模型结构的细节,更重要的是,它们经过了万亿Token的训练,模型里的权重参数已经是完成度很高的可用状态。对于基于开源大模型做训练的车企而言,要做的工作是寻找或建立能够适用于车用场景的数据集,再进行微调训练。
在开源基础大模型上面做定制,从而训练出微调大模型的过程,就好比学霸上完了高中,并将他脑袋里成熟的神经网络复刻到你的脑袋里,然后你再去上大学选个专业,在这个专业领域单兵突进,继续深造。
比如,现在有专门面向医疗行业、财税行业的大模型,同样是在基础大模型之训练出来的。
再比如,一小撮程序员训练出来志在消灭大多数程序员的软件开发者大模型——GitHub Copilot,和最近让码农们闻风丧胆的Davin。

图片来源:GitHub
和华为系、百度系相比,蔚小理的GPT在参数量上也许小了一个数量级,但这并不意味着NOMI GPT们在车载场景下的专项能力一定会低于华为/百度系车企,几百亿参数的大模型足以将文本形式的所有人类知识压缩进去。
再者,加大训练数据规模同样可以提升大模型的表现,可以认为,数据集的作用并不亚于模型参数。
在2023年的微软Build大会上,Andrej Karpathy大神在阐释参数量和Token数量对大模型性能的影响时,对2020年问世的GPT-3和2023年问世的LLaMA-65B做过对比。

图片来源:微软Build大会
2020年发布的GPT-3的参数量为1750亿,训练Token数量为3000亿(随着时间的增加,会继续追加训练数据规模),LLaMA-65B的参数量为650亿,用于训练的Token数量介于1万亿-1.4万亿之间。
GPT-3参数量更大,表现却不及LLaMA-65B,背后的主要原因就在于LLaMA进行了更加充分的训练。
在训练上,其他玩家也可以站在巨人的肩膀上,向训练完备、表现出色的大模型投喂更多的训练语料。而且,在一定程度上,语料库也是现成的。
过去几十年,除了寻求如何设计更加可泛化的推理机制,设计可通向人类通用能力和常识的神经网络和大模型,人工智能研究人员还把大量的精力放在了孜孜不倦地构建包含大量常识语料库的知识库上面。
比如,用于训练和评估用于检测机器释义文本模型的Identifying Machine-Paraphrased Plagiarism、通用文本分类数据集Wikipedia、Reddit 和 Stack Exchange、QA 数据集Quoref 、 基于文本的问答数据集TriviaQA等等。
这背后有大量的工作要做。因为,和基础大模型可以通过无监督、无需标注的数据进行训练不同,在基础大模型之上进行微调训练时,需要通过有监督和基于人类反馈的强化学习形式,在标注过的高质量数据集上进行训练,通过对话形式进行专项能力训练,工作量也不容小觑。

图片来源: Andrej Karpathy
大模型自有其训练机制,在车端的部署路径也日益清晰。
按照难易程度和各个头部车企的大模型上车实践,可以做出一个比较清晰合理的判断:大模型将全面改造智能座舱,并有望在几年后真正部署在智能驾驶方案中。
智能座舱是人机交互集中发生的地方,人和机器或智能体的交互主要体现在机器对人类意图的理解、记忆和推理三个方面,大模型天然具备超强的理解和生成能力,并可以通过提高上下文的长度增强记忆能力,再加上智能座舱的容错能力特别强,所以,从技术和应用场景的契合度上,大模型和智能座舱可谓天作之合,也必然大幅度提升人机交互体验。
理想汽车在MEGA发布会上,介绍了Mind GPT的四大落地场景:百科老师、用车助手、出行助手和娱乐助手,基本总结了大模型技术当前在智能座舱领域的几个用武之地。

图片来源:理想汽车
自动驾驶领域也是大模型可以大显身手的地方。
大模型对自动驾驶的意义目前主要体现在加快算法开发和模型迭代速度上,比如毫末智行发布的大模型DriveGPT雪湖·海若可以在“训练阶段”进行数据的筛选、挖掘、自动标注,在“仿真阶段”生成测试场景。
不过,由于自动驾驶对安全性的要求特别高,对实时性的要求也极为严苛,要在车端部署大模型形式的自动驾驶方案还需要很长一段时间。
业界还在探索在“开发阶段”利用大模型(生成式的多模态大视觉语言模型),比如理想汽车最近和清华联手开发的DriveVLM,部署在英伟达Orin X上的话,推理能力需要0.3秒。
0.3秒是个什么概念?就是如果你以20米每秒(对应72公里每小时)的速度开车,0.3秒可以跑出去6米。。。这还仅仅是考虑到了实时性这个单一因素,还没有涉及到大模型的幻觉对安全性的威胁。
所以,大模型改造智能座舱可谓指日可待,但用在自动驾驶方面,只能说任重道远,未来可期。
总体上,面对激烈的市场竞争,本土车企不能放过任何一个风口,大模型这种超级大的风口绝对不能错过,其他车企今年会陆续传来大模型上车的消息,这一点基本上毋庸置疑。
接下来这一年,大家可能需要做好迎接各种车载大模型炫技的测评视频满天飞的准备,不过,也不用太理会他们说的怎么天花乱坠,大模型从“能用”到真正“好用”,再到产生破圈效应,诸位且耐心等一等吧。
来源:第一电动网
作者:HiEV
本文地址:https://www.d1ev.com/kol/230610
文中图片源自互联网,如有侵权请联系admin#d1ev.com(#替换成@)删除。




先估价再买车,买的放心开的安心
您的询价信息
已经成功提交我们稍后会联系您进行报价!







 京公网安备
11010502033163号
京公网安备
11010502033163号