关注并标星电动星球News
每天打卡阅读
更深刻理解汽车产业变革
————————
出品:电动星球 News
作者:毓肥
上周五,特斯拉正式揭开了 DOJO 的神秘面纱。
在当时的首发文章里面,我们重点回顾了整场发布会的主要内容。由于 AI Day 的主角太多,所以 DOJO 有关的部分,我们在保证阅读体验的基础上,更多地只能讲疗效。

但如果不能跟大家交流更多 DOJO 的信息,我们觉得 AI Day 白看了。
因为这场发布会是特斯拉正式转型,或者说正式成为人工智能公司的节点。而 DOJO 则是这家人工智能公司最底层,也是最重要的硬件产品。
但到底应该怎么理解 DOJO,怎样用更易懂的语言让大家看到特斯拉的巧思、创新,甚至是狂想?
最终我们决定,把这台 1.1EFLOPS 算力的 DOJO Pod,当成一个「人」:
那么作为「细胞」存在的,应该是特斯拉自研的人工智能训练「节点」;
作为「器官」存在的,则是 354 个节点构成的 D1 芯片;
而 25 个 D1 芯片组成的「Training Tile」,又构成了 DOJO Pod 的「功能系统」;
最终 120 个 Tile 组成的 DOJO Pod,则是一个完整的超算。
也就是说,特斯拉从细胞级别的地基开始,完整地构建了一整套超算系统的大厦。除了英伟达和谷歌,目前还没有哪家科技企业展现过这样的能力,更不用说车企。
今天的开头有点长,因为我们希望尽量写一篇更多朋友能理解的文章,而不是简单地堆砌术语。
接下来,我们就从最基本的单位开始,带大家在 DOJO Pod 里面走一遍。
一、DOJO 的细胞
特斯拉将 DOJO 的最小组成单位,命名为「Training Node」,训练节点。它是 DOJO 的细胞,更是特斯拉芯片哲学的最精简具现。

每一块 D1 芯片里面拥有354 个这样的节点,我们可以近似地将它理解为「核心」。也就是说,每一块 D1 可以近似理解成 354 核的芯片。但这个「核」与我们谈论自家电脑酷睿 i5、i7 时的「四核」、「八核」依然有明显的区别。
1. 所以,「Training Node」究竟是个啥?
6 月底出席 2021 CVPR 会议时,特斯拉 AI 部门主管 Andrej 表示,一共有 5760 个英伟达 A100 GPU,为特斯拉的深度学习网络服务。
CPU 和 GPU,可能是我们接触最多的芯片名词,而一般来讲,GPU 比 CPU 更适合用于深度计算。

为什么 GPU 更适合?因为从结构上来说,GPU 更适合大规模、低精度的运算,CPU 更适合小规模(相对小)、高精度运算。
我们决定不去解释 CPU 和 GPU 之间的结构差别,因为一个比喻就能搞定:CPU 是几位大学教授研究数论,GPU 是几百位中学生算一元二次方程。
于是问题就变得更容易理解了:为什么中学生比大学教授更适合深度学习?
因为深度学习的本质,就是低精度+大规模的卷积运算。对于神经网络运算,「核心规模」比「单个核心的精度」权重更高。
说得再简单一点,就是让 10 位数学教授算 10 万条一元方程,一定没有 1 万个中学生算得快。
所以,特斯拉需要把自家的人工智能芯片设计成类 GPU 架构,也就是单个核心无须特别复杂,但核心数要多。
「Training Node」,就是一种接近 GPU 核心结构的产物,但由于它对特斯拉自己的算法高度优化,所以比英伟达卖的万能钥匙 GPU 稍微复杂;但它又要比纯粹的 CPU 更适合深度学习,所以规模更大。
2. 造细胞的世界观有了,方法论呢?
从这一小节开始,有一个词语希望大家牢记:带宽 Bandwidth。
AI Day 的首发文章里,我们提到过算力并不是特斯拉的核心诉求。
一块芯片的算力来源于半导体工艺,而特斯拉只负责选择工艺(甲方),不负责生产(乙方,台积电);只要特斯拉有钱买目前最先进的工艺,台积电一定可以把晶体管给你堆得满满当当。
但如何将芯片设计得完美符合需求,也就是如何安排晶体管,这是砸钱无法解决的,也是真正衡量一家芯片公司技术实力的天平。
特斯拉的 AI 硬件方法论很简单:一切为带宽服务。
进入 AI 时代,所有标榜 AI 性能的芯片厂商,都在追求带宽最大化。比如英伟达为自家 A100 芯片配备了 HBM 超高带宽显存,并且通过高带宽桥接器 NV-Link 连接多个 A100。这也是特斯拉在 DOJO 正式使用之前选择英伟达的重要原因。
为什么深度学习需要海量带宽?
再来一个不算准确,但足够形象的比喻:写下 10 条大学向量代数习题需要的纸,一定比写 1 万条一元二次方程需要的纸少。深度学习需要的是大规模低精度运算,产生的低精度数据量非常可观。
目前 AI 界硬件公司的思路是带宽开源,而软件公司的方向则是算法节流。至于算力,本质上归半导体代工厂管。
3. 所以如何从最基础的部分开始,最大化 DOJO 的带宽?

这块东西我们下面会详细说,叫做 Training Tile。之所以提上来,是需要解释一个概念——Tile 这个单词用于芯片领域,并不是特斯拉的首创,它起源于 1997 年的麻省理工。
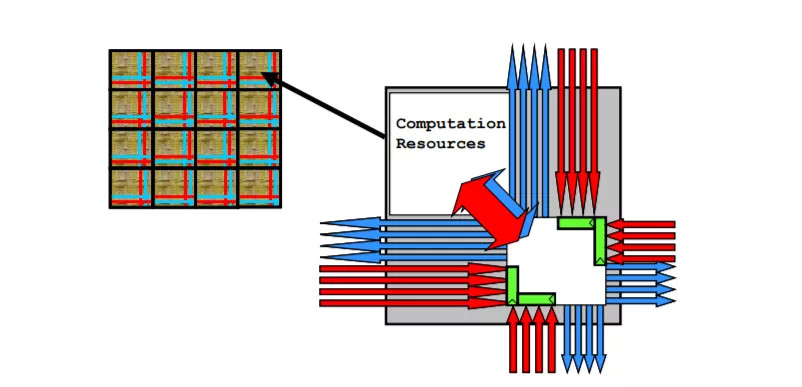
上面的芯片结构图叫做 RAW,基于麻省理工 1997 年的一篇论文首次提及的「划分方式」打造,这种方式就叫做 Tile。
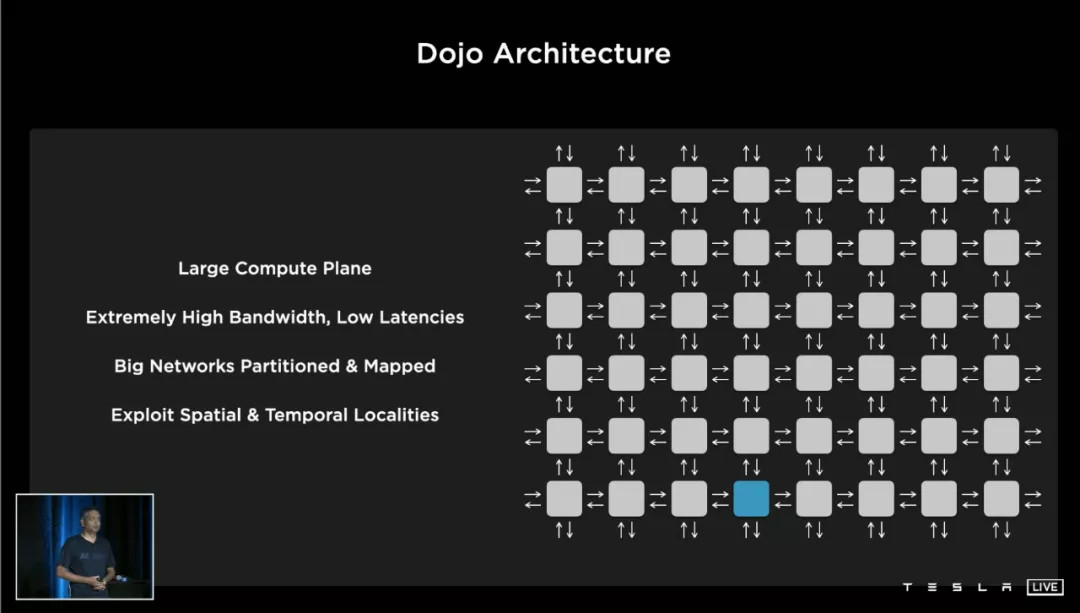
Tile 的特点,是它把处理单元、SRAM 缓存、网络接口等等模块集成在一个区域内,不同的区域之间通过 NoC,network on chip(片上网络)互连。它不像是一种架构,而更像一种排列方式。
这种排列方式的好处,是扩展能力更强(比如堆叠更多核心)、核心之间连接方式多样且迅速。
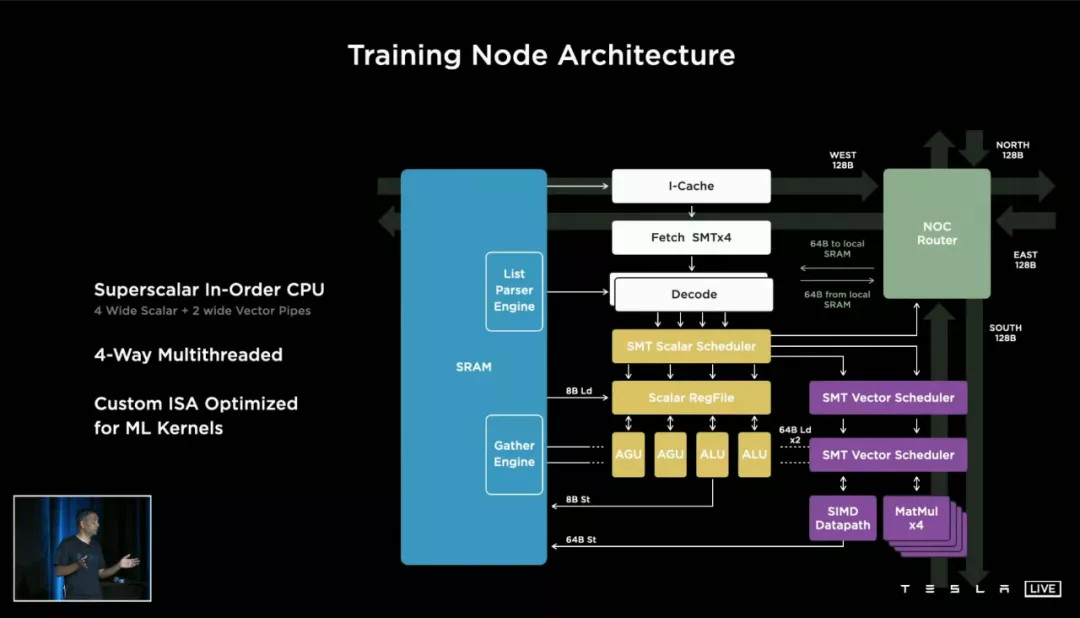
回到特斯拉的 Training Node 结构图。负责计算的单元并不是本文讨论的重点,右上角这一块「NoC Router 片上网络路由器」,才是 Training Node 的精髓。
特斯拉为每一个 Node 设计了东南西北(上下左右)各 64bit 的片上NoC通道,这使得 Node 之间核心堆叠和数据传输的难度大大降低——或者打个比喻,堆乐高的时候你发现每一块积木都能从上下左右往外砌。
内核间多方向的片上 NoC 通道,其实是 AI 芯片的共同趋势。像是此前拿下单芯片面积之最的 Cerebras WSE,其内部同样使用了 NoC 片上网络通信。
二、D1 芯片
聊到这里,我们冲出了 Training Node,来到了芯片层面。
28 个月之后,特斯拉重拾自己芯片设计公司的头衔,带来了第二款自主设计的芯片产品。
和 2019 年在车规级的笼子里跳舞不一样,这次的 D1 芯片是数据中心级别的产品——这意味着特斯拉终于可以毫无顾忌放肆一把。
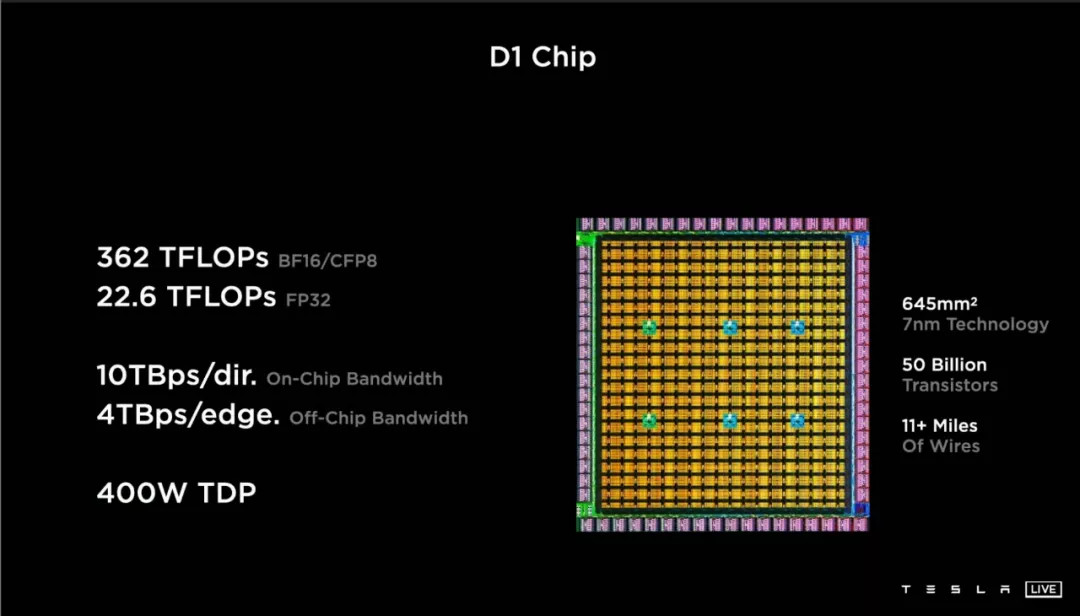
这枚 D1 芯片的基本参数是:645 平方毫米面积、500 亿个晶体管、11 英里的内部走线、400W TDP(Thermal Design Power 热设计功耗,指正常工作环境的负载功耗)。
首先要说的,是 D1 晶体管密度非常高,每平方毫米晶体管数量达到了 7752 万个,这已经打平了使用台积电二代 7 纳米工艺的苹果 A13,超越了初代台积电 7 纳米工艺打造的英伟达 A100。
台积电的功劳就说到这,接下来讲特斯拉做了什么。
1. 10TB 每秒的on-chip bandwidth 片上带宽,这是极其恐怖的数字。
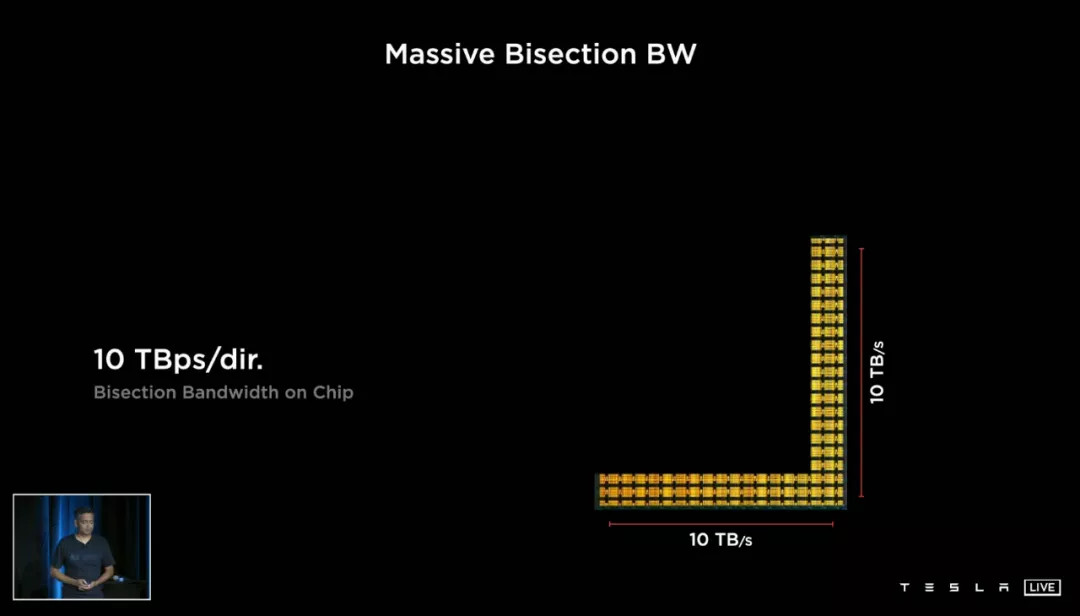
没有对比就没有伤害,2019 年同样标榜自己 on-chip 带宽业内顶尖的英特尔 Stratix 10MX(一款最高拥有 10TOPS FP32 精度算力的通用计算芯片),这个指标为 1TB 每秒。
但这里 10TB 指的更像是最理想结果,D1 芯片每个 node 每个方向的带宽是 512GB,10TB 指的是每一行(列)node 同时传输数据时达到的最大带宽。
2. 另一个指标是 4TB 每秒的 off-chip bandwidth 片外带宽。
这里涉及到另一个名词:SerDes,全称 Serializer-Deserializer,序列化器与反序列化器。
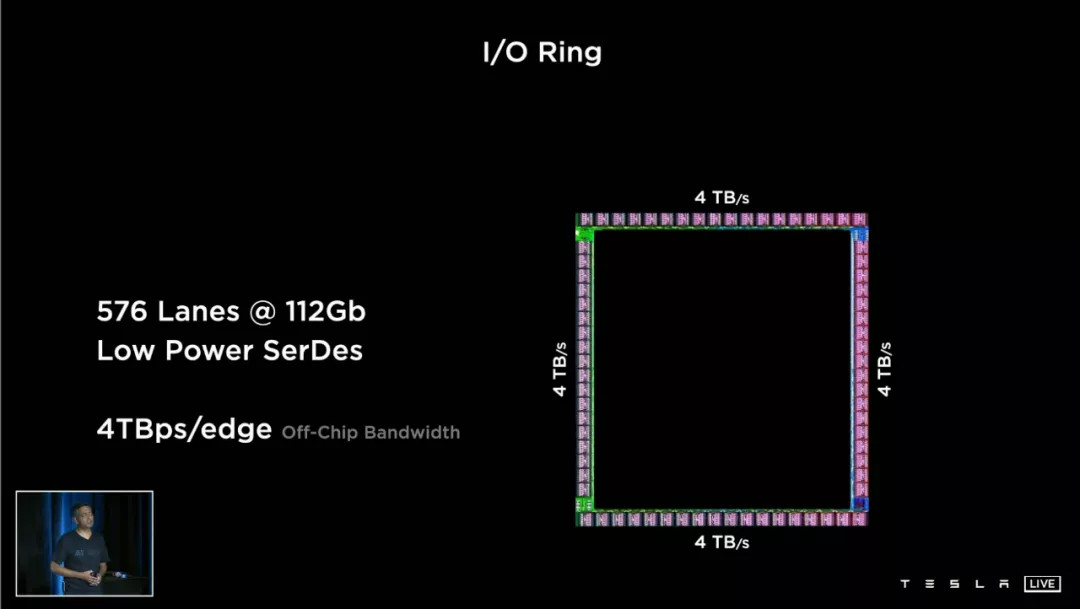
我们还是只讲疗效:SerDes 是一种同等体积下增加带宽、减少信号数量的工具,可以降低芯片功耗和封装成本。
目前单一 SerDes 接口最快的传输速率达到了 112Gbps——而特斯拉在每一块 D1 芯片的四条边上,都累计布置了 576 个 112Gb 带宽的 SerDes 接口。
4TB 每秒到底有多快?特斯拉用了一张 PPT 作对比:
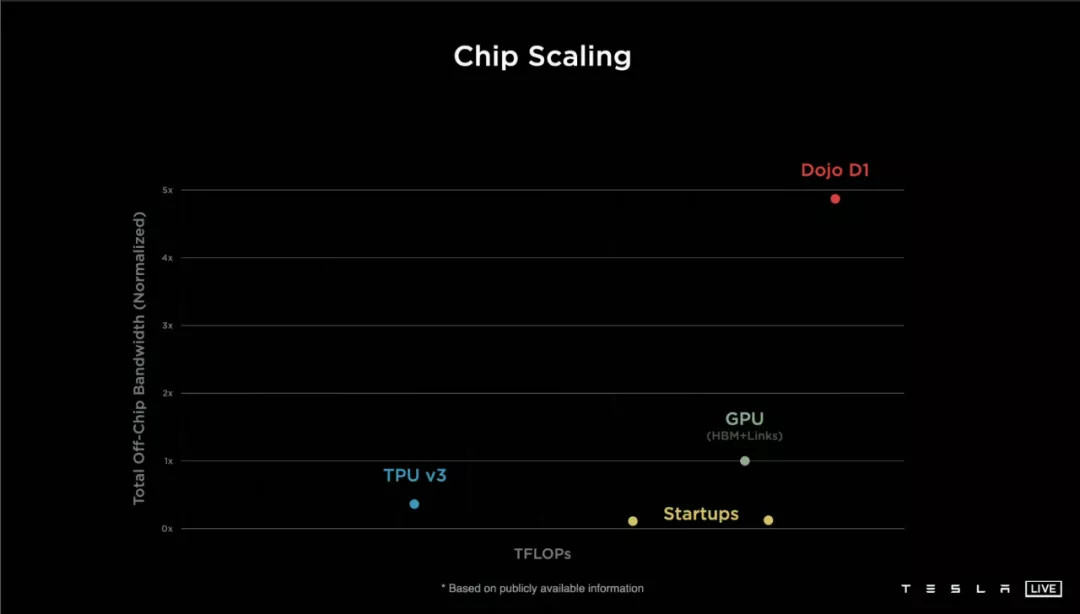
不过有些「营销术语」我们得挑出来,比如用作对比的谷歌 TPU V3 已经是 2018 年的老产品,3 个月前 TPU V4 登场,各项指标并不比 D1 差。
三、Training Tile
下图所示,就是组成 DOJO Pod 的基本单元。

每一块 Tile 上面都封装着 25 块 D1 芯片,总算力高达 9PFLOPS,芯片四周扩散出每边 9TB 每秒的超高速通信接口,然后上下则分别连接着水冷散热,以及供电模块。
到这里,DOJO 的超高带宽系统已经完整呈现:
D1 芯片内上下左右各 10TB 每秒→D1芯片间上下左右各 4TB 每秒→5x5 D1 芯片方阵各边 9TB 每秒→Tile 与 Tile 之间最高 36TB 每秒。
一个 GB 级别的「小」数字都没有。

为了实现这些数字,特斯拉最终设计了「可能是芯片工业史上最大的 MCM 封装」——这是特斯拉 Autopilot 硬件高级主管 Ganesh Venkataramanan 的原话。
但特斯拉的工程魔法还没结束。

上面是谷歌 TPU V3 的散热示意图。一块主板上四枚TPU用一个共同的水路散热。到了 TPU V4,水冷系统变得复杂,效率也提升了:

但这种冷却系统有一个弊端:无法兼顾供电元件,需要另外考虑供电部分的散热。
一个 DOJO Tile 上面有 25 块 D1 芯片,最保守估计功耗也超过了 10kW,120 个 Tile 功耗相当于一个 10 桩 V2 超充站火力全开——超充站的变压器也是需要散热的。
特斯拉的解决方案有点像电脑领域的「分体水冷主板」:用垂直水路将芯片、供电元件连接起来,用最少的水路搞定多个散热需求。
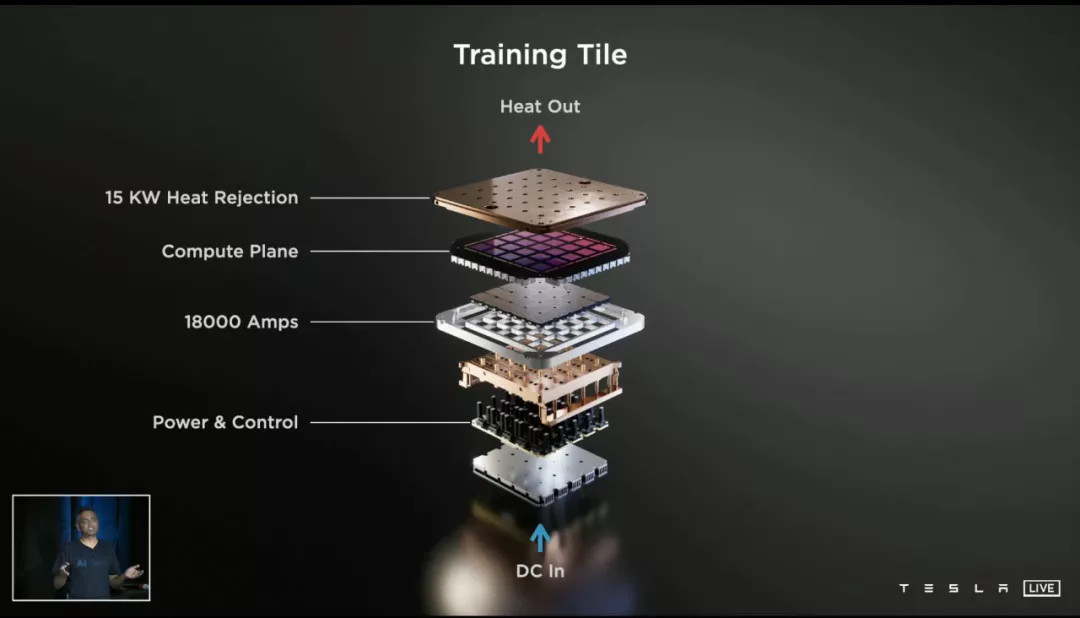
根据 AI Day 的 PPT,每一块 Tile 都配备了高达 15kW 散热能力的水冷系统,但最终结构却简单得过分:

四、DOJO Pod
120 个 Tile 组成的 Pod,是 DOJO 的最终形态。1.1Exaflops,则是一个 DOJO Pod 的最高算力。
Pod 在这个语境下,指的是「通过网络手段连接在一起的多台计算机」,但一个 Pod 可以做到多大,业内没有明确规定。

但这里要强调一下,1.1E 算力并非在超算界用的 FP32 完整精度测得,而是 BF16/CFP8 精度。
BF16 精度,又叫 BrainFloat16,是为深度学习而优化的新数字格式,它保证了计算能力和计算量的节省,而预测精度的降低幅度最小,目前支持 BF16 精度的,已经有英特尔、谷歌、ARM 等等巨头。而 CFP8 则是特斯拉自优化的精度。
「节省」是什么意思?举个例子,FP32 精度就是你告诉别人「我在广州市天河区天河路 218 号天环广场地上一层 L128 号商铺」,而 BF16 就是你告诉别人「我在广州天环广场」。
那么如果计算 FP32 精度,DOJO Pod 是个怎样的水平?
单个 D1 芯片可以达到 22.6T 的 FP32算力,那么整个 Pod 理论上就是 22.6x25x120=67800TFLOPS 的 FP32 算力。
现在我们看看 2021 年上半年的 HPC 全球超算 TOP500 排行榜:
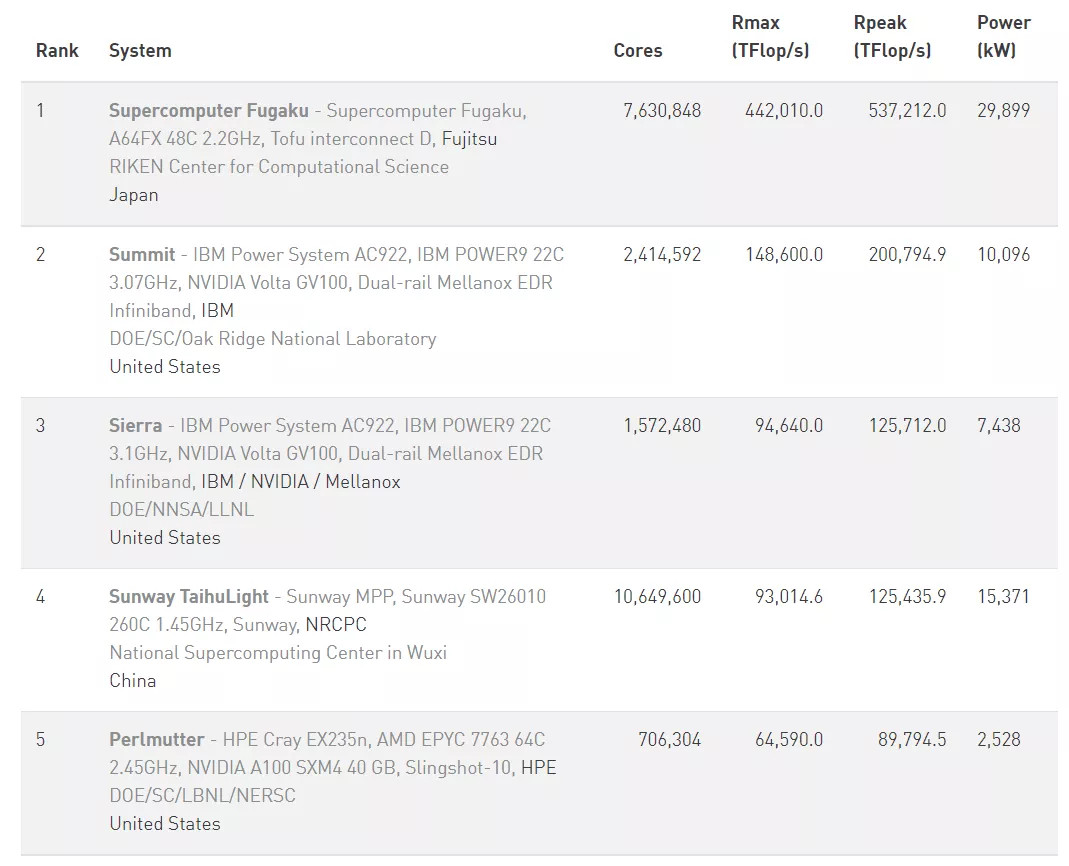
67800TFLOPS 的算力可以排在第五位(看 Rmax 算力那一列),刚好把曾经的「全球最强 AI 计算机」,服役于美国国家能源研究科学计算中心(NERSC)的 Perlmutter挤掉。

但达到这个成绩,特斯拉只用了一个 Pod(机柜),而 Perlmutter有 4 个长机柜。
最后
文章到这里就写完了。
非常庆幸我能在 4000 字以内,将最希望与大家分享的 DOJO 相关细节写完,并且尽自己的能力,把术语解释得稍微浅显一点。
但对于特斯拉来说,它作为一家人工智能企业的生涯,也许才刚刚开始。
马斯克在 AI Day 上面说「特斯拉其实也是全球最大的机器人生产公司,我们生产的是轮上机器人」。然后他带来了真正的特斯拉机器人,并且明年就会有原型了。
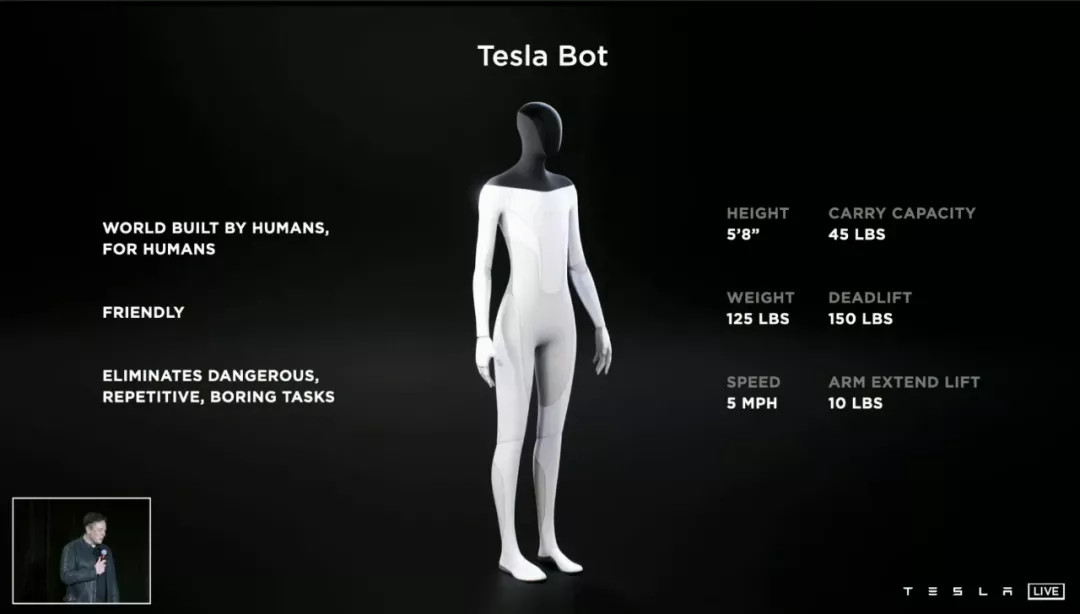
无论是智能电动汽车,还是人工智能,都还处于雏形阶段。特斯拉、谷歌,或者国内的新造车「御三家」、华为、百度,它们更像是「探索者」,而不是「收获者」。
也正因为人类下一轮生产力大解放还处在黎明前,我们才能看到趋势,预测变化,并且亲眼见证变革。
DOJO 不会是特斯拉的终点,也不会是人工智能的终点,但多年之后回过头来,它也许会是个「预兆」,或者说「开篇」。
(完)
来源:第一电动网
作者:电动星球News蟹老板
本文地址:https://www.d1ev.com/kol/154651
文中图片源自互联网,如有侵权请联系admin#d1ev.com(#替换成@)删除。




先估价再买车,买的放心开的安心
您的询价信息
已经成功提交我们稍后会联系您进行报价!








 京公网安备
11010502033163号
京公网安备
11010502033163号