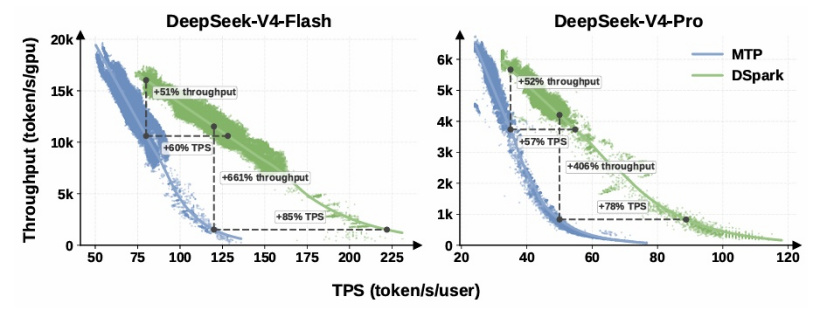
今日,DeepSeek与北京大学联合发布了DSpark推理加速框架,旨在提升大语言模型在高并发环境中的推理效率。DSpark框架通过半自回归架构和置信度调度验证机制,优化了候选生成质量和验证阶段的计算资源占用,显著提高了单用户生成速度。该框架已部署于DeepSeek-V4-Flash与DeepSeek-V4-Pro的预览版服务引擎中,相比之前的单token推测解码基线MTP-1,在同等吞吐量水平下,单用户生成速度提升了60%至85%。
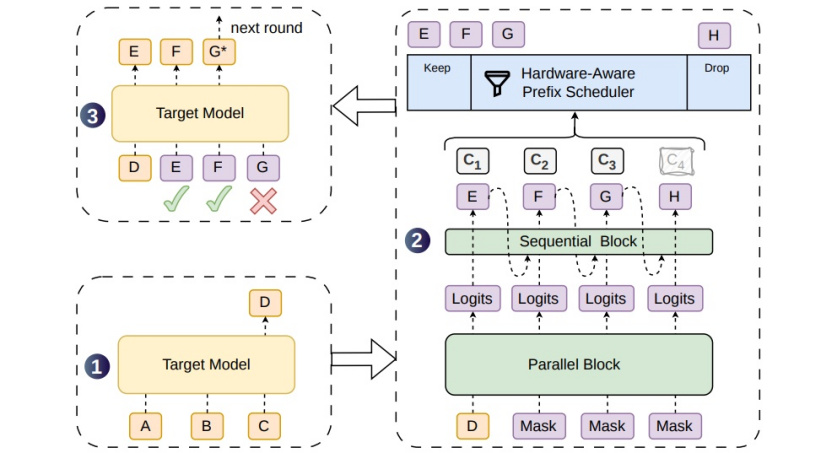
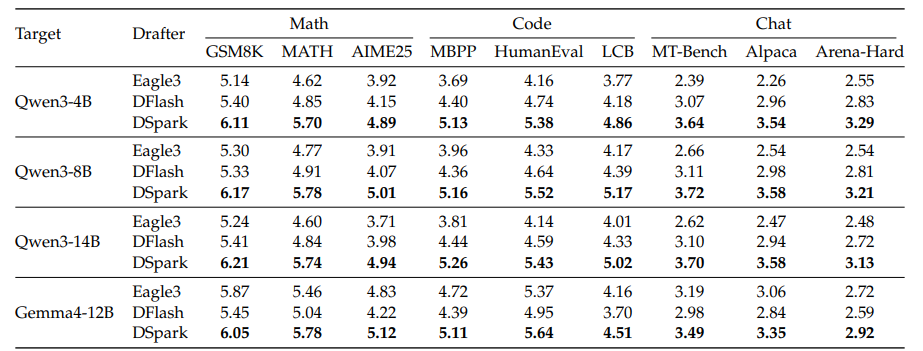
DSpark框架的创新之处在于其半自回归架构,该架构结合了并行主干网络和轻量级顺序模块,有效提升了参数效率和接受长度。在验证调度阶段,DSpark通过模型输出的置信度分数,动态决定验证多长的候选前缀,优先分配计算资源给存活概率最高的token,从而最大化全局吞吐量。实验结果表明,DSpark在多个测试领域上的表现均优于自回归草稿模型Eagle3和并行草稿模型DFlash。
在生产部署方面,DSpark草稿模型已与DeepSeek-V4-Flash及DeepSeek-V4-Pro预览版共同部署,实现了系统优化和异步调度,以适应在线生产环境的需求。实际系统集成中,DSpark展现出负载自适应的验证预算分配能力,有效提升了吞吐量和单用户生成速度。目前,DSpark、DFlash和Eagle3三种草稿模型的训练代码、评估脚本及模型检查点已在GitHub的DeepSpec项目中开源。
来源:一电快讯
返回第一电动网首页 >
以上内容由AI创作,如有问题请联系admin#d1ev.com(#替换成@)沟通,AI创作内容并不代表第一电动网(www.d1ev.com)立场。
文中图片源自互联网或AI创作,如有侵权请联系邮件删除。







 京公网安备
11010502033163号
京公网安备
11010502033163号