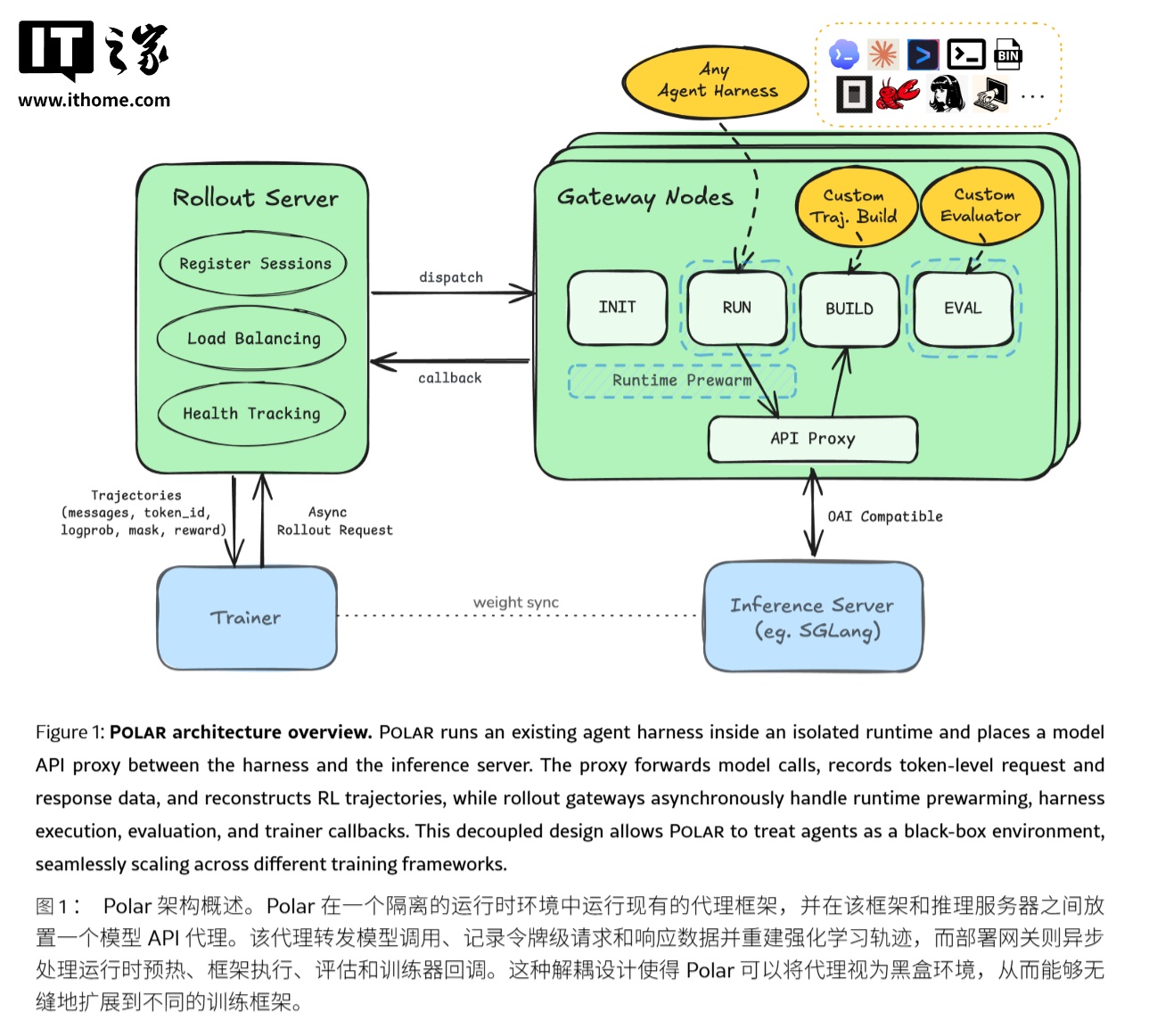
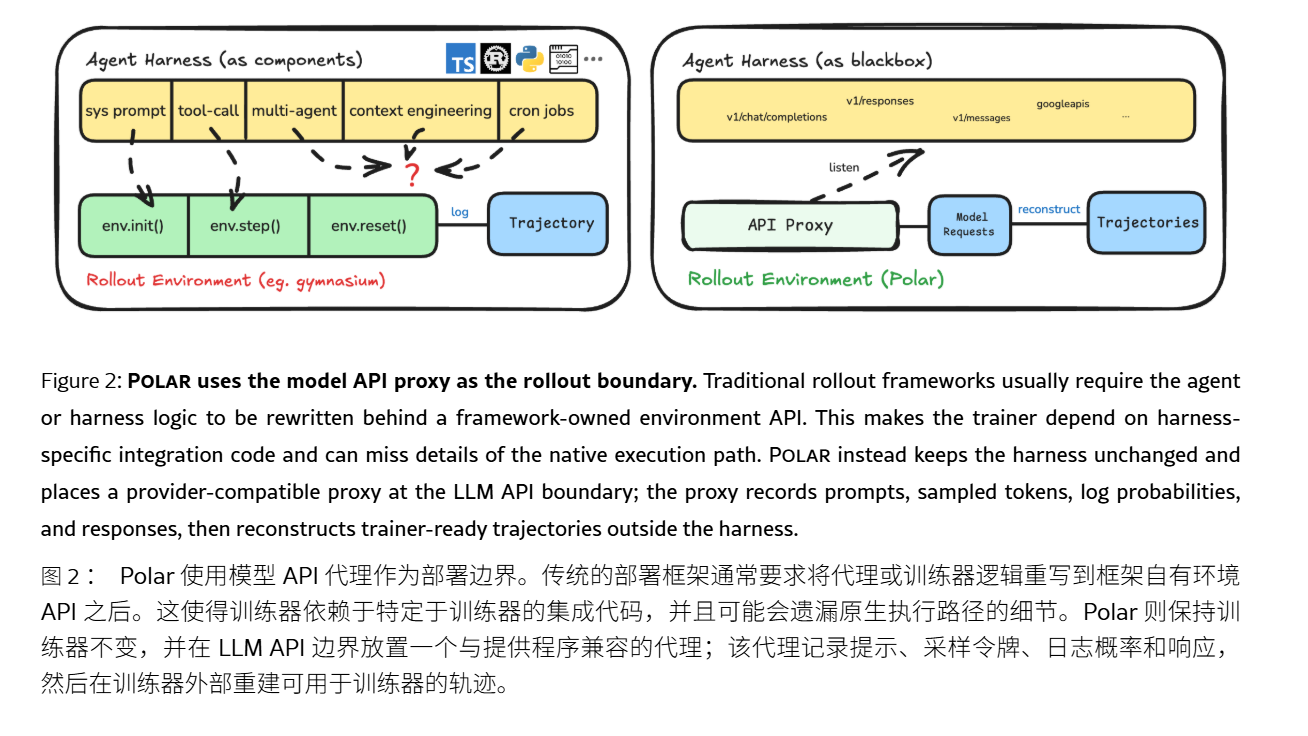
近日,英伟达研究团队发布了一个名为Polar的开源框架,该框架能够在不破坏原有工具调用、上下文组织和补丁提交方式的前提下,使Codex、ClaudeCode、QwenCode等现有智能体框架接入GRPO(广义相对策略优化)训练。GRPO是一种强化学习训练的优化方法,通过依据奖励信号调整模型策略,使模型在多步决策任务中学会更优动作。Polar的核心设计在于将智能体与模型之间的接口作为训练边界,而不是将执行框架本身改造成环境,从而降低了接入成本并保留了原生执行细节。
Polar框架由rolloutserver和gatewaynode组成,前者负责任务提交、会话调度、状态持久化和回调接收;后者负责会话执行全生命周期,包括运行时启动、执行框架准备、轨迹构建、结果评测和资源回收。此外,Polar还优化了初始化、运行中、后处理流程,并设置了READY缓冲区,以减少长尾任务对GPU训练的阻塞。在软件工程任务的实验中,Polar配合GRPO训练后,在SWE-BenchVerified的pass@1分数上实现了显著提升,效率方面也得到了极大的改善,如prefix_merging相比per_request,将训练步骤中的更新次数大幅降低,墙钟时间也显著缩短。
来源:一电快讯
返回第一电动网首页 >
以上内容由AI创作,如有问题请联系admin#d1ev.com(#替换成@)沟通,AI创作内容并不代表第一电动网(www.d1ev.com)立场。
文中图片源自互联网或AI创作,如有侵权请联系邮件删除。







 京公网安备
11010502033163号
京公网安备
11010502033163号