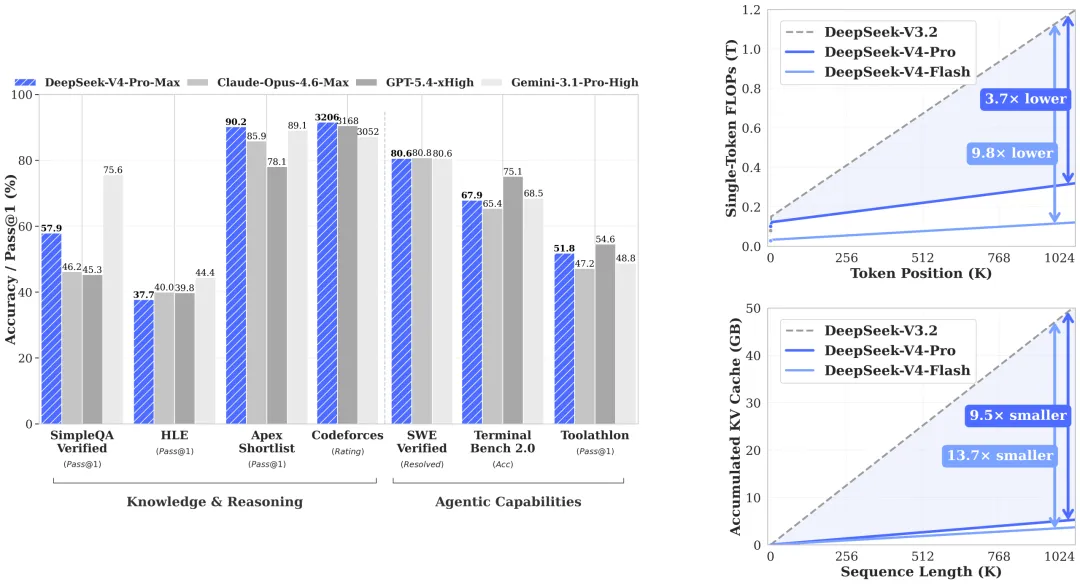
4月24日,摩尔线程与智源FlagOS合作,成功为旗舰级AI训推一体全功能GPU MTTS5000完成了DeepSeek-V4-Flash模型的Day-0适配。DeepSeek-V4-Flash模型采用混合专家(MoE)架构,拥有284B的总参数量和13B的激活参数,支持百万token上下文长度,预训练数据超过32Ttoken。在最大推理力度模式下,其推理能力接近Pro版本。
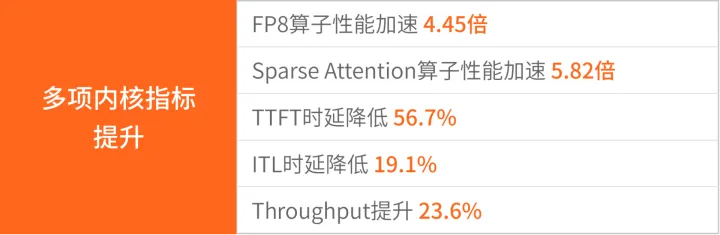
此次适配中,DeepSeek-V4模型首次采用了“FP4+FP8”混合精度策略,而国内主流AI芯片多以BF16为主。摩尔线程凭借原生FP8支持能力,更高效地承载了DeepSeek-V4的前沿精度设计。MTTS5000 GPU内置硬件级FP8 TensorCore加速单元,与传统BF16/FP16相比,数据位宽减半,显存带宽压力降低50%,理论计算吞吐量翻倍。
为充分发挥MTTS5000的FP8优势,FlagOS团队对DeepSeek-V4模型进行了FP8量化。双方技术团队在FP8算子与SparseAttention算子上进行了系统级分析,并在编译优化与自动调优两大方向取得了重大突破。摩尔线程已多次实现国产大模型的Day-0即时适配,包括MiniMaxM2.7、智谱GLM-5等。

来源:一电快讯
返回第一电动网首页 >
以上内容由AI创作,如有问题请联系admin#d1ev.com(#替换成@)沟通,AI创作内容并不代表第一电动网(www.d1ev.com)立场。
文中图片源自互联网或AI创作,如有侵权请联系邮件删除。







 京公网安备
11010502033163号
京公网安备
11010502033163号