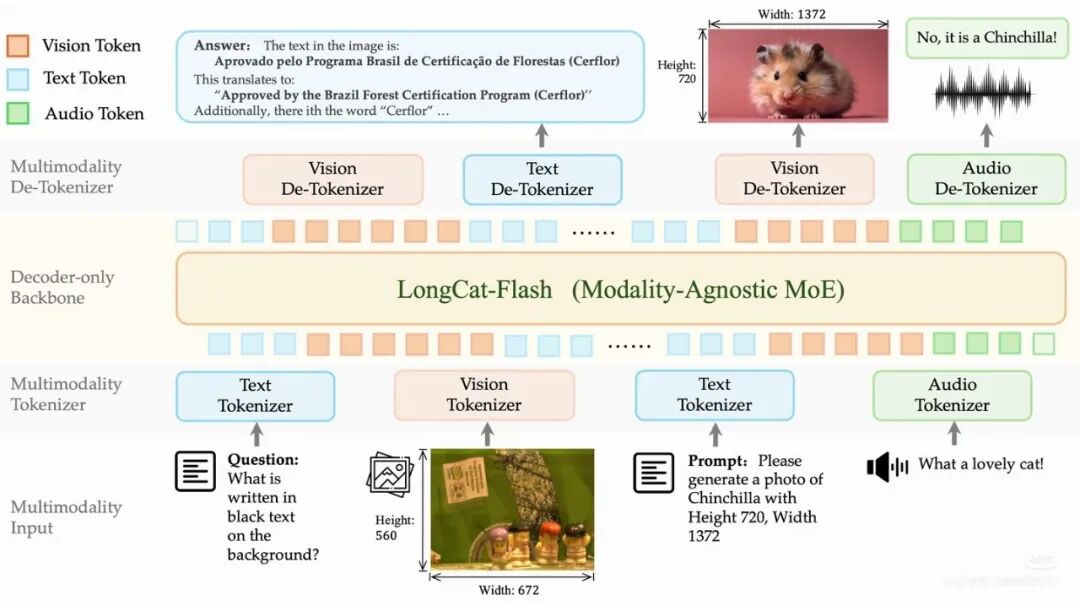
今日,美团宣布发布原生多模态大模型LongCat-Next,该模型通过将图像、语音与文本统一映射为同源的离散Token,实现了对不同物理信号的统一建模。LongCat-Next模型采用了DiNA(Discrete Native Autoregressive)离散原生自回归架构,打破了模态间的隔阂,使得AI在处理文字、图像、语音时,都转换为预测下一个Token的任务。美团还宣布将LongCat-Next模型和离散分词器开源,以促进开发者基于此构建能感知、理解并作用于真实世界的AI。
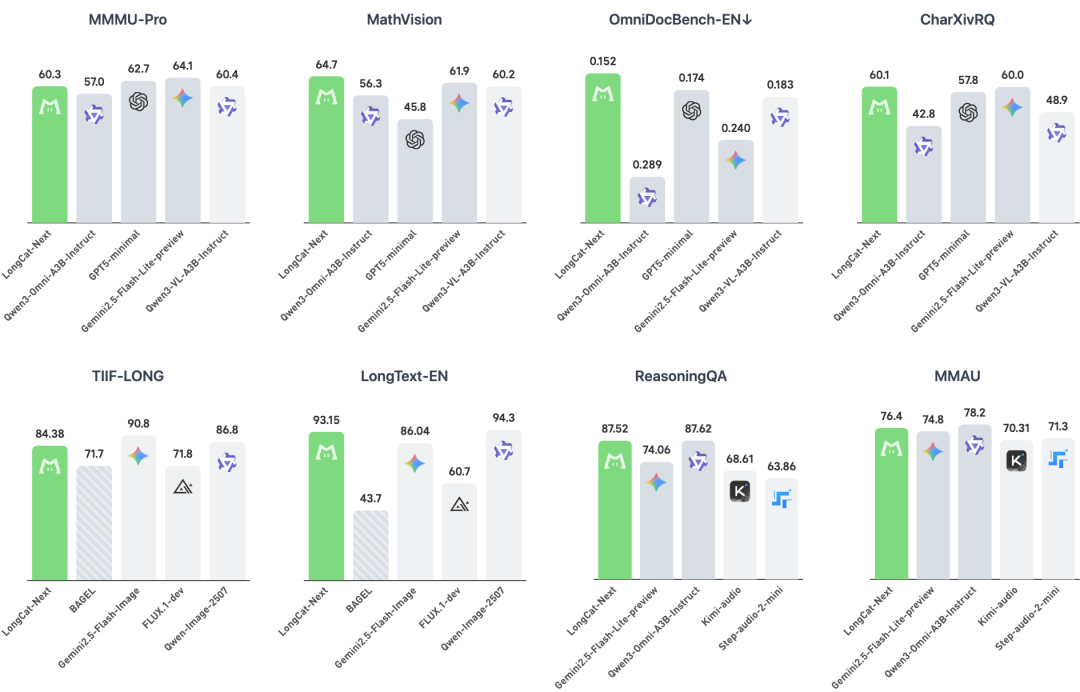
LongCat-Next基于DiNA范式设计,使用LongCat-Flash-LiteMoE作为基座进行训练,展现出在视觉理解、图像生成、音频等多个维度上与多模态专用模型相当甚至领先的性能。在OmniDocBench上,LongCat-Next的表现超越了Qwen3-Omni和专用视觉模型Qwen3-VL。在图像生成和理解、纯文本任务以及音频领域,LongCat-Next均达到了领先水平,证明了原生多模态训练未削弱语言核心能力。此外,模型还支持低延迟的并行文本语音生成与可定制的语音克隆,提升了语音交互的自然度和个性化。

来源:一电快讯
返回第一电动网首页 >
以上内容由AI创作,如有问题请联系admin#d1ev.com(#替换成@)沟通,AI创作内容并不代表第一电动网(www.d1ev.com)立场。
文中图片源自互联网或AI创作,如有侵权请联系邮件删除。







 京公网安备
11010502033163号
京公网安备
11010502033163号