3月26日,
谷歌研究院推出一项名为TurboQuant的全新极端压缩算法,旨在解决AI大模型中的键值缓存(KVCache)内存瓶颈问题。该算法通过压缩高维向量数据,减少内存消耗,同时保持AI模型的预测性能。TurboQuant的核心底层技术包括量化Johnson-Lindenstrauss(QJL)和PolarQuant,这两项技术共同作用,能够在不牺牲性能的前提下,大幅降低键值缓存的内存占用。
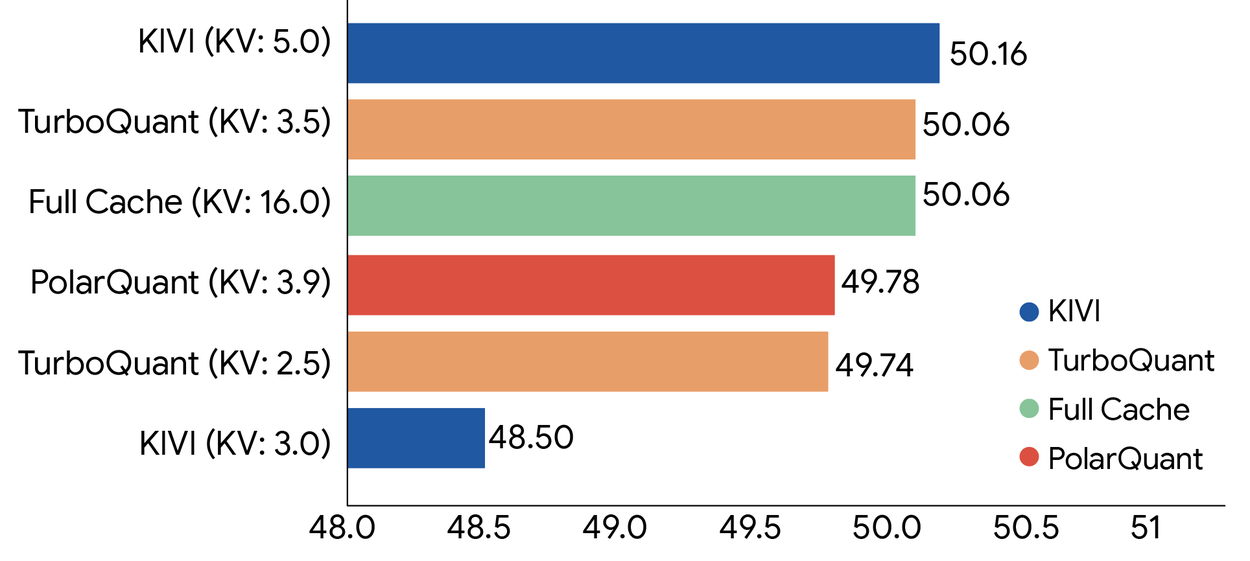
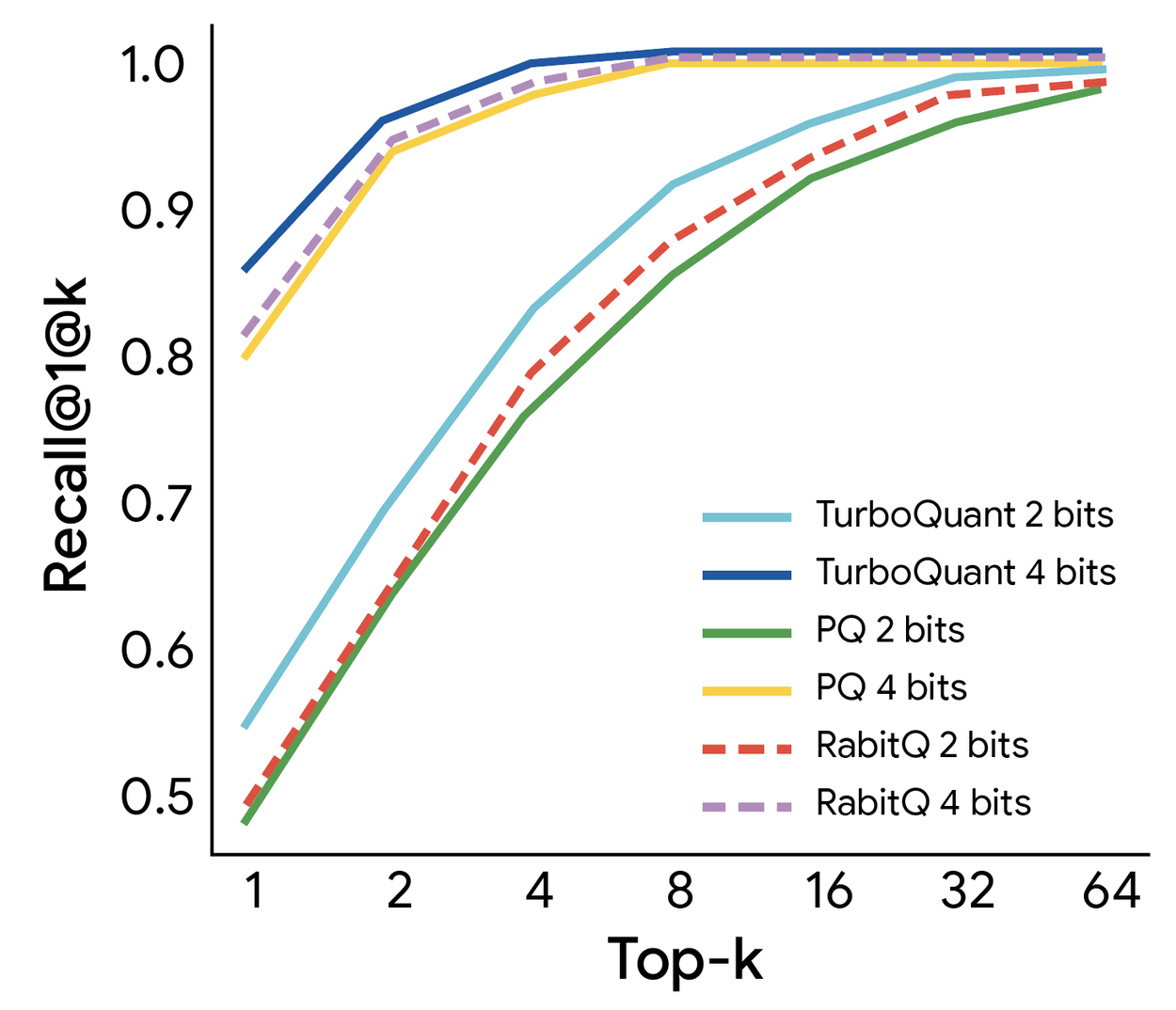
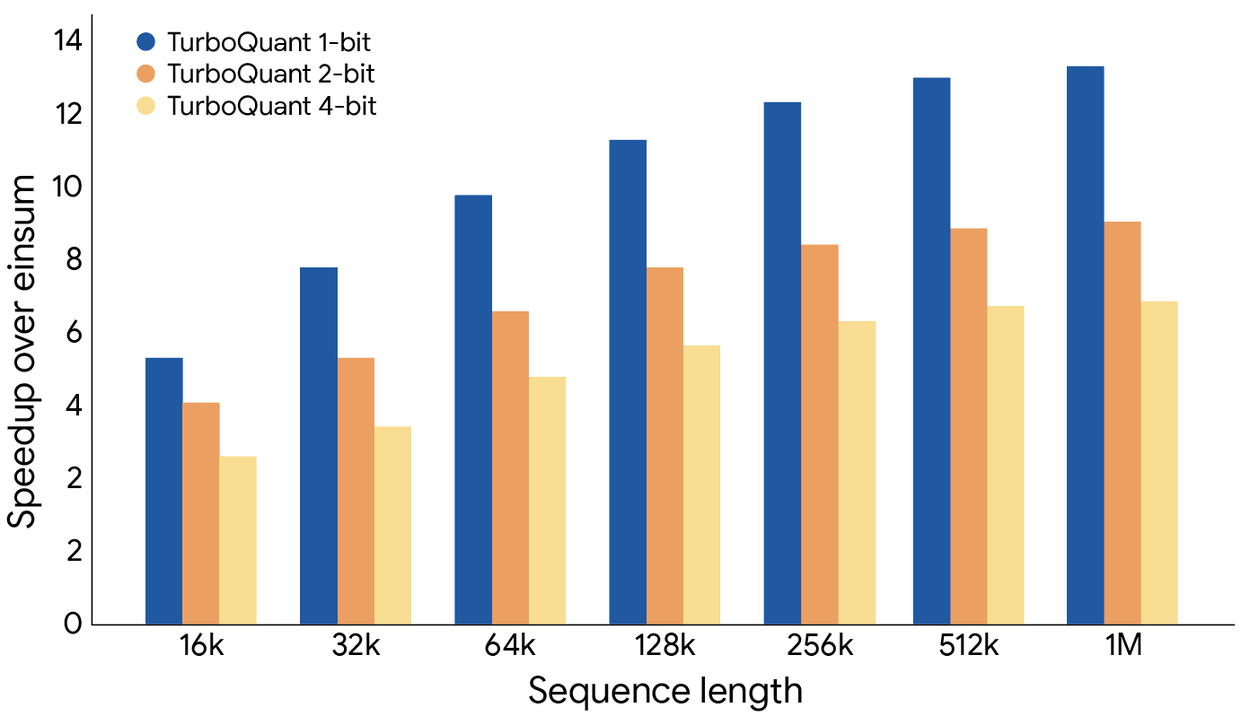
TurboQuant的运行机制分为两个关键步骤:首先,利用PolarQuant方法进行主体压缩,将数据向量转换为极坐标,省去了数据归一化步骤,消除了传统方法的内存开销;其次,QJL算法处理微小误差,仅需1比特的残差压缩算力,确保模型计算出精准的注意力分数。在Gemma和Mistral等开源大模型上的基准测试显示,TurboQuant能将键值缓存压缩至3比特,实现零精度损失,并将内存占用降低至1/6。此外,在 NVIDIA H100 等主流硬件上,TurboQuant 可将注意力计算速度提升最高约 8 倍,同时不需要额外训练或微调即可部署。
谷歌TurboQuant压缩算法的推出对存储芯片市场产生了影响,导致相关巨头股价全线飘绿,美光科技下跌4%,西部数据下跌4.4%,希捷下跌5.6%,闪迪下跌6.5%。
来源:一电快讯
返回第一电动网首页 >
以上内容由AI创作,如有问题请联系admin#d1ev.com(#替换成@)沟通,AI创作内容并不代表第一电动网(www.d1ev.com)立场。
文中图片源自互联网或AI创作,如有侵权请联系邮件删除。







 京公网安备
11010502033163号
京公网安备
11010502033163号