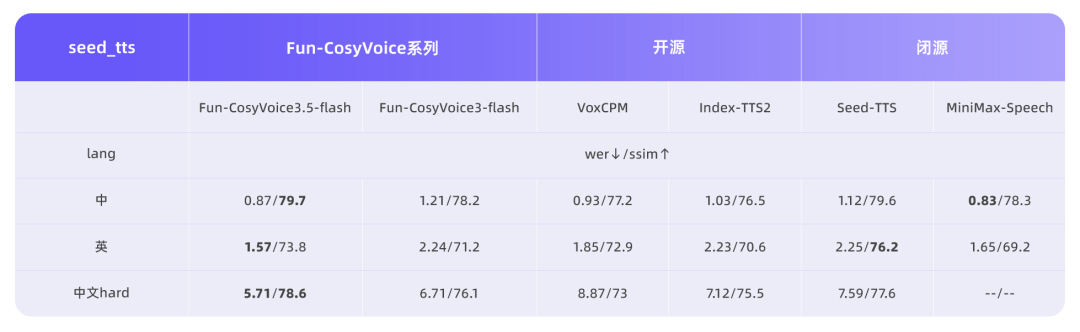
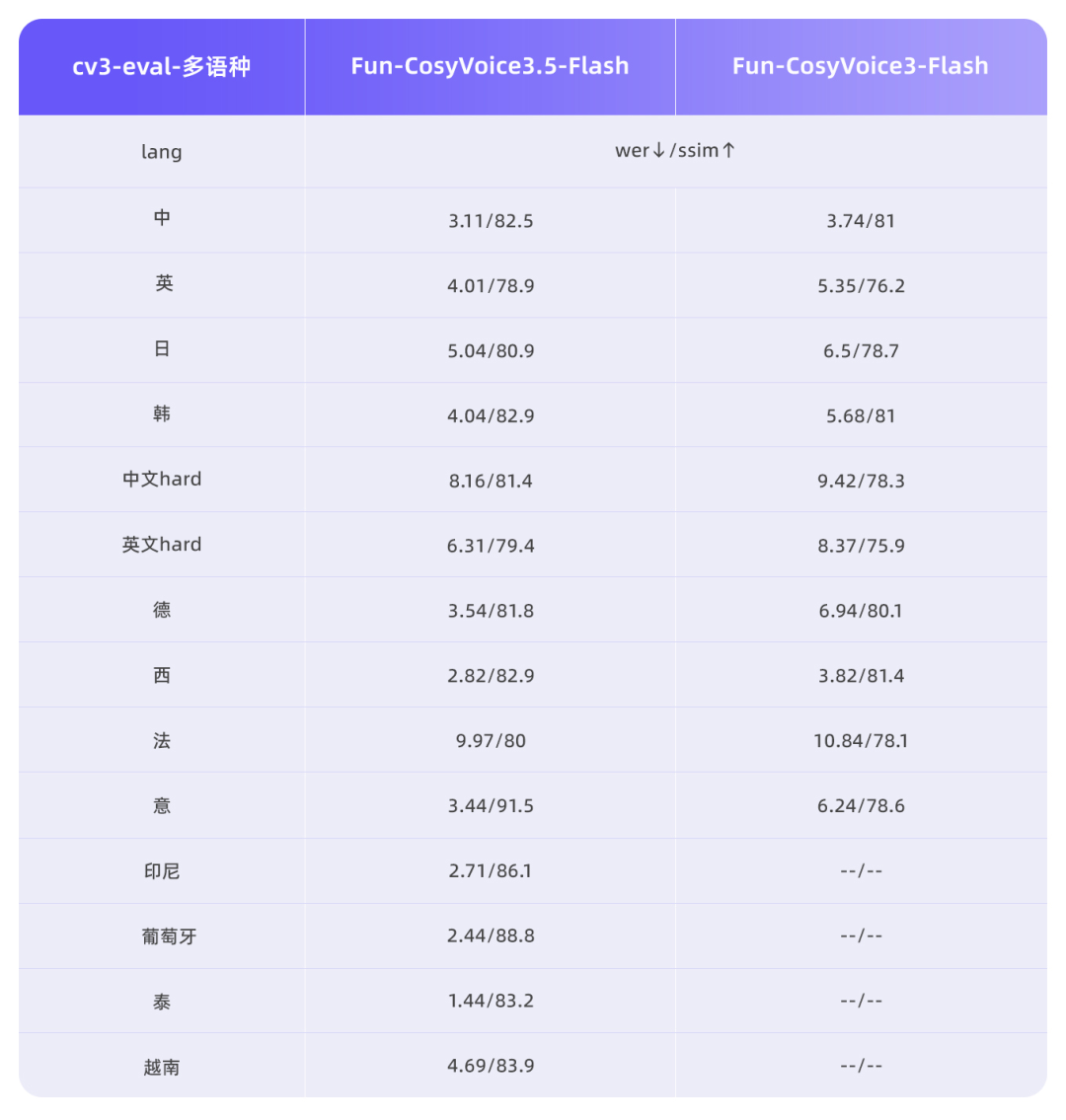
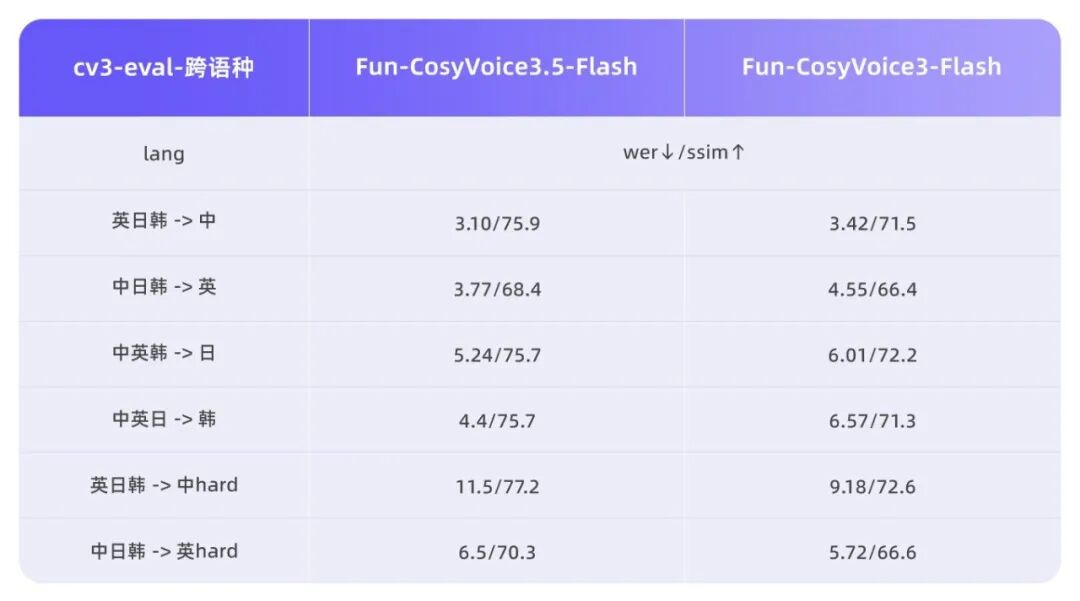
3月2日,阿里通义实验室语音团队发布了两款新型语音生成模型Fun-CosyVoice3.5与Fun-AudioGen-VD,这两款模型均支持通过自然语言指令控制语音生成,但各自应用方向不同。Fun-CosyVoice3.5模型在Instruct-TTS方向实现能力升级,支持FreeStyle指令控制生成效果,用户可以用自然语言描述表达方式,模型即可理解并生成相应表达。该模型新增支持泰语、印尼语、葡萄牙语、越南语,并在13种语言的WER和SpkSim客观指标上保持业内领先。针对生僻字、复杂语句等容易读错的场景专项优化,生僻字读错率显著降低。性能方面,Tokenizer帧率减半,首包延迟降低35%,提升了实时交互场景下的响应速度和流畅度。
Fun-AudioGen-VD模型则支持根据自然语言描述生成目标音色、情绪表达和完整听觉场景,实现“人物+场景”的一体化声音生成。该模型能够根据基础属性、音质特征、情绪表达和角色模拟等生成声音,并能叠加背景环境音、模拟空间混响效果、还原设备听感滤镜以及支持动态环境互动,打造沉浸式听觉场景。
来源:一电快讯
返回第一电动网首页 >
以上内容由AI创作,如有问题请联系admin#d1ev.com(#替换成@)沟通,AI创作内容并不代表第一电动网(www.d1ev.com)立场。
文中图片源自互联网或AI创作,如有侵权请联系邮件删除。







 京公网安备
11010502033163号
京公网安备
11010502033163号